m4 mac mini本地部署ComfyUI,测试Flux-dev-GGUF的workflow模型10步出图,测试AI绘图性能,基于MPS(fp16),优点是能耗小和静音by Liu Yue/2024-12-09 标签: 10 ai ComfyUI dev Flux fp16 GGUF m4 Mac mini mps workflow 优点 本地 模型 步出 测试 绘图 能耗 静音 m4 mac mini已经发布了一段时间,针对这个产品,更多的是关于性价比的讨论,如果抛开各种补贴不论,价位上和以前发布的mini其实差别不大,真要论性价比,各种windows系统的mini主机的价格其实是吊打苹果的。 本次我们针对m4 mac mini的AI性能做个测试,使用目前泛用性最广的AI工作流软件:ComfyUI框架,基于MPS(fp16)模式进行测试。 Mac Os 本地部署ComfyUI &......了解更多
使用腾讯混元(HunYuanVideo)视频模型FP8量化版本来生成绅士动画,模型体积30G,8G甜品卡可玩,2秒视频需要15分钟by Liu Yue/2024-12-08 标签: 15 30G 8G FP8 HunYuanVideo 体积 使用 分钟 动画 卡可玩 模型 混元 版本 甜品 生成 绅士 腾讯 视频 量化 需要 腾讯混元(HunYuanVideo)视频模型发布以来,视频效果有口皆碑,但由于推理门槛比较高,消费级显卡用户望而却步,最近大神Kijai发布了FP8量化版本模型,使得甜品卡用户也有了一餐秀色的可能。 本次我们利用HunYuanVideo量化版模型来生成绅士视频。 本地部署ComfyUI 首先需要本地部署ComfyUI框架,克隆官方项目:git clone https://github.com......了解更多
MaskGCT,AI语音克隆大模型本地部署(Windows11),基于Python3.11,TTS,文字转语音by Liu Yue/2024-10-28 标签: ai MaskGCT Python3.11 TTS Windows11 克隆 基于 文字 本地 模型 语音 部署 前几天,又一款非自回归的文字转语音的AI模型:MaskGCT,开放了源码,和同样非自回归的F5-TTS模型一样,MaskGCT模型也是基于10万小时数据集Emilia训练而来的,精通中英日韩法德6种语言的跨语种合成。数据集Emilia是全球最大且最为多样的高质量多语种语音数据集之一。 本次分享一下如何在本地部署MaskGCT项目,让您的显卡再次发烧。 安装基础依赖 首先确保本地已经安装好Py......了解更多
CosyVoice多语言、音色和情感控制模型,one-shot零样本语音克隆模型本地部署(Win/Mac),通义实验室开源by Liu Yue/2024-07-07 标签: CosyVoice Mac shot win 克隆 实验室 开源 情感 控制 本地 样本 模型 语言 语音 通义 部署 音色 近日,阿里通义实验室开源了CosyVoice语音模型,它支持自然语音生成,支持多语言、音色和情感控制,在多语言语音生成、零样本语音生成、跨语言声音合成和指令执行能力方面表现卓越。 CosyVoice采用了总共超15万小时的数据训练,支持中英日粤韩5种语言的合成,合成效果显著优于传统语音合成模型。 CosyVoice支持one-shot音色克隆 :仅需要3~10s的原始音频,即可生成模拟音色,甚至包括韵律、情感等细节。在......了解更多
ChatTTS,语气韵律媲美真人的开源TTS模型,文字转语音界的新魁首,对标微软Azure-ttsby Liu Yue/2024-05-31 标签: Azure ChatTTS TTS 媲美 对标 开源 微软 文字 模型 真人 语气 语音 韵律 魁首 前两天 2noise 团队开源了ChatTTS项目,并且释出了相关的音色模型权重,效果确实非常惊艳,让人一听难忘,即使摆在微软的商业级项目Azure-tts面前,也是毫不逊色的。 ChatTTS是专门为对话场景设计的文本转语音模型,例如大语言助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。目前在huggingface中的开源版本为4万小时训练且未SFT的版本。 本次分享一下......了解更多
苹果AppleMacOs系统Sonoma本地部署无内容审查(NSFW)大语言量化模型Causallmby Liu Yue/2024-03-09 标签: AppleMacOs CausalLM NSFW Sonoma 内容 审查 本地 模型 系统 苹果 语言 部署 量化 最近Mac系统在运行大语言模型(LLMs)方面的性能已经得到了显著提升,尤其是随着苹果M系列芯片的不断迭代,本次我们在最新的MacOs系统Sonoma中本地部署无内容审查大语言量化模型Causallm。 这里推荐使用koboldcpp项目,它是由c++编写的kobold项目,而MacOS又是典型的Unix操作系统,自带clang编译器,也就是说MacOS操作系统是可以直接编译C语言的。 首先克隆koboldcpp项目......了解更多
无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14Bby Liu Yue/2024-02-28 标签: 14B CausalLM Win11 中文 内容 审查 无所不谈 本地 模型 百无禁忌 语言 部署 目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被“玩”坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt)来操纵LLM执行不当行为。内容审查可以帮助识别和过滤这些潜在的攻击,确保LLM按照既定的安全策略和道德标准运行。 但我们今天讨论的是无内容审查机制的大模型,在中文领域公开的模型中,能力相对比较强的有阿里的 Qwen-14B 和清华的 ChatGLM3-6B。 &n......了解更多
苹果AppleMacOs最新Sonoma系统本地训练和推理GPT-SoVITS模型实践by Liu Yue/2024-02-21 标签: AppleMacOs gpt Sonoma SoVITS 实践 推理 最新 本地 模型 系统 苹果 训练 GPT-SoVITS是少有的可以在MacOs系统下训练和推理的TTS项目,虽然在效率上没有办法和N卡设备相提并论,但终归是开发者在MacOs系统构建基于M系列芯片AI生态的第一步。 环境搭建 首先要确保本地环境已经安装好版本大于6.1的FFMPEG软件:(base) ➜ ~ ffmpeg -versionffmpeg version 6.1.1 Copyright (c) 2000-2023 the FFmpeg ......了解更多
自然语言开发AI应用,利用云雀大模型打造自己的专属AI机器人by Liu Yue/2024-02-02 标签: ai 专属 云雀 利用 应用 开发 打造 机器人 模型 自己 自然语言 如今,大模型层出不穷,这为自然语言处理、计算机视觉、语音识别和其他领域的人工智能任务带来了重大的突破和进展。大模型通常指那些参数量庞大、层数深、拥有巨大的计算能力和数据训练集的模型。 但不能不承认的是,普通人使用大模型还是有一定门槛的,首先大模型通常需要大量的计算资源才能进行训练和推理。这包括高性能的图形处理单元(GPU)或者专用的张量处理单元(TPU),以及大内存和高速存储器。说白了,本地没N卡,就断了玩大模型的念想吧。 &nb......了解更多
离线生成双语字幕,一键生成中英双语字幕,基于AI大模型,ModelScopeby Liu Yue/2024-01-29 标签: ai ModelScope 一键 双语 基于 字幕 模型 生成 离线 英双语 制作双语字幕的方案网上有很多,林林总总,不一而足。制作双语字幕的原理也极其简单,无非就是人声背景音分离、语音转文字、文字翻译,最后就是字幕文件的合并,但美中不足之处这些环节中需要接口api的参与,比如翻译字幕,那么有没有一种彻底离线的解决方案?让普通人也能一键制作双语字幕,成就一个人的字幕组? 人声背景音分离 如果视频不存在嘈杂的背景音,那么大多数情况下是不需要做人声和背景音分离的,但考虑到背景音可能会影响语音转文字......了解更多
如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Faceby Liu Yue/2024-01-15 标签: Bert Face Hugging vits2 如何 快速 本地 模型 训练 语音 部署 Hugging Face是一个机器学习(ML)和数据科学平台和社区,帮助用户构建、部署和训练机器学习模型。它提供基础设施,用于在实时应用中演示、运行和部署人工智能(AI)。用户还可以浏览其他用户上传的模型和数据集。Hugging Face通常被称为机器学习界的GitHub,因为它让开发人员公开分享和测试他们所训练的模型。 本次分享如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face。 本......了解更多
首次引入大模型!Bert-vits2-Extra中文特化版40秒素材复刻巫师3叶奈法by Liu Yue/2024-01-06 标签: 40 Bert Extra vits2 中文 叶奈法 复刻 巫师 引入 模型 特化 素材 首次 Bert-vits2项目又更新了,更新了一个新的分支:中文特化,所谓中文特化,即针对中文音色的特殊优化版本,纯中文底模效果百尺竿头更进一步,同时首次引入了大模型,使用国产IDEA-CCNL/Erlangshen-MegatronBert-1.3B大模型作为Bert特征提取,基本上完全解决了发音的bad case,同时在情感表达方面有大幅提升,可以作为先前V1.0.1纯中文版本更好的替代。 更多情报请参见Bert-vits2项目官网:https......了解更多
Bert-vits2-v2.2新版本本地训练推理整合包(原神八重神子英文模型miko)by Liu Yue/2023-12-18 标签: Bert miko v2.2 vits2 八重 原神 推理 整合 本地 模型 版本 神子 英文 训练 近日,Bert-vits2-v2.2如约更新,该新版本v2.2主要把Emotion 模型换用CLAP多模态模型,推理支持输入text prompt提示词和audio prompt提示语音来进行引导风格化合成,让推理音色更具情感特色,并且推出了新的预处理webuI,操作上更加亲民和接地气。 更多情报请参见Bert-vits2官网:https://github.com/fishaudio/Bert-VITS2/releases/tag/v2.2&......了解更多
Bert-vits2新版本V2.1英文模型本地训练以及中英文混合推理(mix)by Liu Yue/2023-12-08 标签: Bert mix V2.1 vits2 中英文 以及 推理 本地 模型 混合 版本 英文 训练 中英文混合输出是文本转语音(TTS)项目中很常见的需求场景,尤其在技术文章或者技术视频领域里,其中文文本中一定会夹杂着海量的英文单词,我们当然不希望AI口播只会念中文,Bert-vits2老版本(2.0以下版本)并不支持英文训练和推理,但更新了底模之后,V2.0以上版本支持了中英文混合推理(mix)模式。 还是以霉霉为例子:https://www.bilibili.com/video/BV1bB4y1R7Nu/ 截取......了解更多
又欲又撩人,基于新版Bert-vits2V2.0.2音色模型雷电将军八重神子一键推理整合包分享by Liu Yue/2023-11-20 标签: Bert vits2V2.0 一键 八重 分享 基于 将军 推理 撩人 整合 新版 模型 神子 雷电 音色 Bert-vits2项目近期炸裂更新,放出了v2.0.2版本的代码,修正了存在于2.0先前版本的重大bug,并且重炼了底模,本次更新是即1.1.1版本后最重大的更新,支持了三语言训练及混合合成,并且做到向下兼容,可以推理老版本的模型,本次我们基于新版V2.0.2来本地推理原神小姐姐们的音色模型。 具体的更新日志请参见官网:https://github.com/fishaudio/Bert-VITS2/releases ......了解更多
声音好听,颜值能打,基于PaddleGAN给人工智能AI语音模型配上动态画面(Python3.10)by Liu Yue/2023-05-18 标签: ai PaddleGAN Python3.10 人工智能 动态 基于 声音 好听 模型 画面 语音 颜值 借助So-vits我们可以自己训练五花八门的音色模型,然后复刻想要欣赏的任意歌曲,实现点歌自由,但有时候却又总觉得少了点什么,没错,缺少了画面,只闻其声,却不见其人,本次我们让AI川普的歌声和他伟岸的形象同时出现,基于PaddleGAN构建“靓声靓影”的“懂王”。 PaddlePaddle是百度开源的深度学习框架,其功能包罗万象,总计覆盖文本、图像、视频三大领域40个模型,可谓是在深度学习领域无所不窥。 Paddle......了解更多
民谣女神唱流行,基于AI人工智能so-vits库训练自己的音色模型(叶蓓/Python3.10)by Liu Yue/2023-05-12 标签: ai Python3.10 so vits 人工智能 叶蓓 基于 女神 模型 民谣 流行 自己 训练 音色 流行天后孙燕姿的音色固然是极好的,但是目前全网都是她的声音复刻,听多了难免会有些审美疲劳,在网络上检索了一圈,还没有发现民谣歌手的音色模型,人就是这样,得不到的永远在骚动,本次我们自己构建训练集,来打造自己的音色模型,让民谣女神来唱流行歌曲,要多带劲就有多带劲。 构建训练集 训练集是指用于训练神经网络模型的数据集合。这个数据集通常由大量的输入和对应的输出组成,神经网络模型通过学习输入和输出之间的关系来进行训练,并且在......了解更多
AI天后,在线飙歌,人工智能AI孙燕姿模型应用实践,复刻《遥远的歌》,原唱晴子(Python3.10)by Liu Yue/2023-05-11 标签: ai Python3.10 人工智能 原唱 在线 复刻 天后 孙燕姿 实践 应用 晴子 模型 遥远 飙歌 忽如一夜春风来,亚洲天后孙燕姿独特而柔美的音色再度响彻华语乐坛,只不过这一次,不是因为她出了新专辑,而是人工智能AI技术对于孙燕姿音色的完美复刻,以大江灌浪之势对华语歌坛诸多经典作品进行了翻唱,还原度令人咋舌,如何做到的? 本次我们借助基于Python3.10的开源库so-vits-svc,让亚洲天后孙燕姿帮我们免费演唱喜欢的歌曲,实现点歌自由。 so-vits-svc是基于VITS的开源项目,VITS(Variat......了解更多
好饭不怕晚,Google基于人工智能AI大语言对话模型Bard测试和API调用(Python3.10)by Liu Yue/2023-03-31 标签: ai api Bard Google Python3.10 不怕 人工智能 基于 好饭 对话 模型 测试 语言 调用 谷歌(Google)作为开源过著名深度学习框架Tensorflow的超级大厂,是人工智能领域一股不可忽视的中坚力量,旗下新产品Bard已经公布测试了一段时间,毁誉参半,很多人把Google的Bard和OpenAI的ChatGPT进行对比,Google Bard在ChatGPT面前似乎有些技不如人。 事实上,Google Bard并非对标ChatGPT的产品,Bard是基于LaMDA模型对话而进行构建的,Bard旨在构建一个对话式的AI系统,使......了解更多
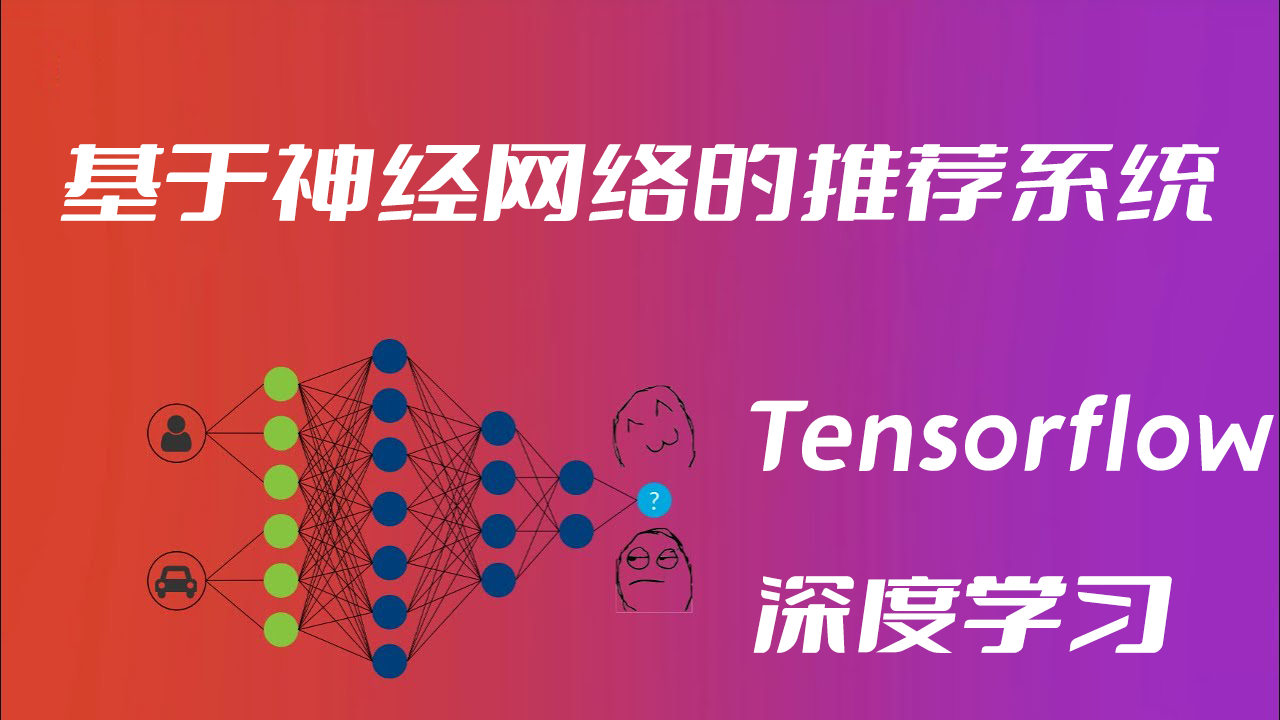
构建基于深度学习神经网络协同过滤模型(NCF)的视频推荐系统(Python3.10/Tensorflow2.11)by Liu Yue/2023-03-30 标签: NCF Python3.10 Tensorflow2.11 协同 基于 学习 推荐 构建 模型 深度 神经网络 系统 视频 过滤 毋庸讳言,和传统架构(BS开发/CS开发)相比,人工智能技术确实有一定的基础门槛,它注定不是大众化,普适化的东西。但也不能否认,人工智能技术也具备像传统架构一样“套路化”的流程,也就是说,我们大可不必自己手动构建基于神经网络的机器学习系统,直接使用深度学习框架反而更加简单,深度学习可以帮助我们自动地从原始数据中提取特征,不需要手动选择和提取特征。 之前我们手动构建了一个小型的神经网络,解决了机器学习的分类问题,本次我们利用深度学习框架Tens......了解更多
本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPTby Liu Yue/2023-03-24 标签: C++ ChatGPT LLaMA MacM1 单机 基于 推理 本地 模型 版本 系统 芯片 语言 运行 部署 OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿、130亿、330亿和650亿这4种参数规模的模型,参数是指神经网络中的权重和偏置等可调整的变量,用于训练和优化神经网络的性能,70亿意味着神经网络中有70亿个参数,由此类推。 在一些大型神经网络中,每个参数需要使用32位或64位浮点数进行存储,这意味着每个参数需要......了解更多
重新定义性价比!人工智能AI聊天ChatGPT新接口模型gpt-3.5-turbo闪电更新,成本降90%,Python3.10接入by Liu Yue/2023-03-06 标签: 3.5 90% ai ChatGPT gpt Python3.10 turbo 人工智能 定义 性价比 成本 接入 接口 更新 模型 聊天 重新 闪电 北国春迟,春寒料峭略带阴霾,但ChatGPT新接口模型gpt-3.5-turbo的更新为我们带来了一丝暖意,使用成本更加亲民,比高端产品ChatGPT Plus更实惠也更方便,毕竟ChatGPT Plus依然是通过网页端来输出,Api接口是以token的数量来计算价格的,0.002刀每1000个token,token可以理解为字数,说白了就是每1000个字合0.01381人民币,以ChatGPT无与伦比的产品力而言,如此低的使用成本让所有市面上其他所有类ChatGPT......了解更多
使用python3.7和opencv4.1来实现人脸识别和人脸特征比对以及模型训练by Liu Yue/2020-01-02 标签: 使用 实现 python3.7 以及 opencv4.1 人脸识别 人脸 模型 训练 特征 OpenCV4.1已经发布将近一年了,其人脸识别速度和性能有了一定的提高,这里我们使用opencv来做一个实时活体面部识别的demo 首先安装一些依赖的库pip install opencv-python pip install opencv-contrib-python pip install numpy pip install pillow ......了解更多