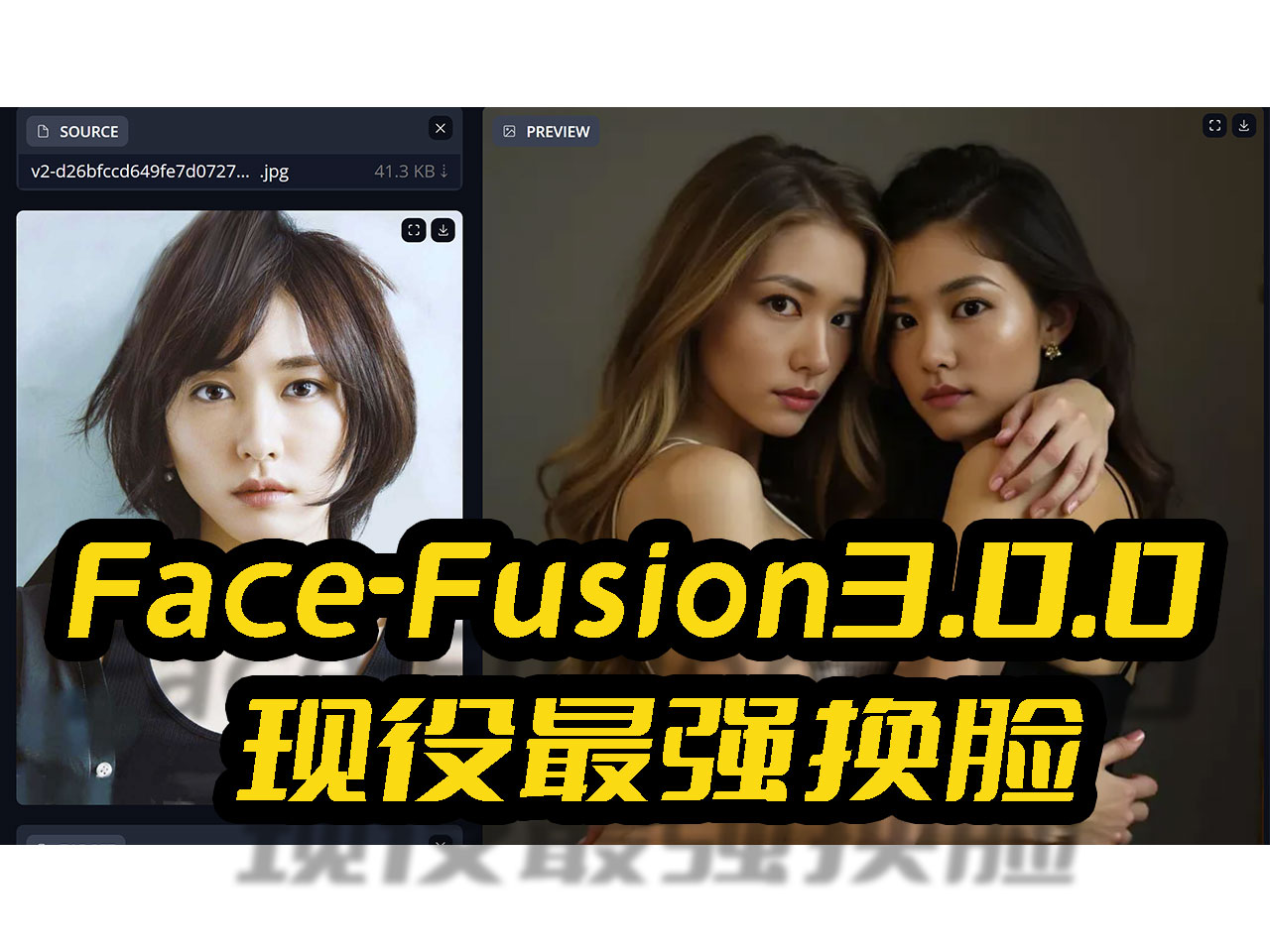
Win11本地部署FaceFusion3最强AI换脸,集成Tensorrt10.4推理加速,让甜品显卡也能发挥生产力by Liu Yue/2024-09-27 标签: ai FaceFusion3 Tensorrt10.4 Win11 加速 发挥 换脸 推理 显卡 最强 本地 甜品 生产力 部署 集成 FaceFusion3.0.0大抵是现在最强的AI换脸项目,分享一下如何在Win11系统,基于最新的cuda12.6配合最新的cudnn9.4本地部署FaceFusion3.0.0项目,并且搭配Tensorrt10.4,提高推理速度和效率,让甜品级显卡也能爆发生产力。 安装最新版本Cuda12.6以及Cudnn9.4 CUDA是NVIDIA公司开发的一种技术,它能让GPU像CPU一样编程,让GPU也能参与到计算中来,......了解更多
苹果AppleMacOs最新Sonoma系统本地训练和推理GPT-SoVITS模型实践by Liu Yue/2024-02-21 标签: AppleMacOs gpt Sonoma SoVITS 实践 推理 最新 本地 模型 系统 苹果 训练 GPT-SoVITS是少有的可以在MacOs系统下训练和推理的TTS项目,虽然在效率上没有办法和N卡设备相提并论,但终归是开发者在MacOs系统构建基于M系列芯片AI生态的第一步。 环境搭建 首先要确保本地环境已经安装好版本大于6.1的FFMPEG软件:(base) ➜ ~ ffmpeg -versionffmpeg version 6.1.1 Copyright (c) 2000-2023 the FFmpeg ......了解更多
Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)by Liu Yue/2023-12-27 标签: 2.3 Bert Colab GPU vits2 云端 免费 平台 推理 最终版 算力 训练 对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更是让JupyterNoteBook的脚本运行形式如虎添翼。 本次我们利用Bert-vits2的最终版Bert-vits2-v2.3和JupyterNoteBook的脚本来复刻生化危机6的人气......了解更多
云端开炉,线上训练,Bert-vits2-v2.2云端线上训练和推理实践(基于GoogleColab)by Liu Yue/2023-12-19 标签: Bert GoogleColab v2.2 vits2 云端 基于 实践 开炉 推理 线上 训练 假如我们一定要说深度学习入门会有一定的门槛,那么设备成本是一个无法避开的话题。深度学习模型通常需要大量的计算资源来进行训练和推理。较大规模的深度学习模型和复杂的数据集需要更高的计算能力才能进行有效的训练。因此,训练深度学习模型可能需要使用高性能的计算设备,如图形处理器(GPU)或专用的深度学习处理器(如TPU),这让很多本地没有N卡的同学望而却步。 GoogleColab是由Google提供的一种基于云的免费Jupyter笔记本环境。它可以帮......了解更多
Bert-vits2-v2.2新版本本地训练推理整合包(原神八重神子英文模型miko)by Liu Yue/2023-12-18 标签: Bert miko v2.2 vits2 八重 原神 推理 整合 本地 模型 版本 神子 英文 训练 近日,Bert-vits2-v2.2如约更新,该新版本v2.2主要把Emotion 模型换用CLAP多模态模型,推理支持输入text prompt提示词和audio prompt提示语音来进行引导风格化合成,让推理音色更具情感特色,并且推出了新的预处理webuI,操作上更加亲民和接地气。 更多情报请参见Bert-vits2官网:https://github.com/fishaudio/Bert-VITS2/releases/tag/v2.2&......了解更多
Bert-vits2新版本V2.1英文模型本地训练以及中英文混合推理(mix)by Liu Yue/2023-12-08 标签: Bert mix V2.1 vits2 中英文 以及 推理 本地 模型 混合 版本 英文 训练 中英文混合输出是文本转语音(TTS)项目中很常见的需求场景,尤其在技术文章或者技术视频领域里,其中文文本中一定会夹杂着海量的英文单词,我们当然不希望AI口播只会念中文,Bert-vits2老版本(2.0以下版本)并不支持英文训练和推理,但更新了底模之后,V2.0以上版本支持了中英文混合推理(mix)模式。 还是以霉霉为例子:https://www.bilibili.com/video/BV1bB4y1R7Nu/ 截取......了解更多
又欲又撩人,基于新版Bert-vits2V2.0.2音色模型雷电将军八重神子一键推理整合包分享by Liu Yue/2023-11-20 标签: Bert vits2V2.0 一键 八重 分享 基于 将军 推理 撩人 整合 新版 模型 神子 雷电 音色 Bert-vits2项目近期炸裂更新,放出了v2.0.2版本的代码,修正了存在于2.0先前版本的重大bug,并且重炼了底模,本次更新是即1.1.1版本后最重大的更新,支持了三语言训练及混合合成,并且做到向下兼容,可以推理老版本的模型,本次我们基于新版V2.0.2来本地推理原神小姐姐们的音色模型。 具体的更新日志请参见官网:https://github.com/fishaudio/Bert-VITS2/releases ......了解更多
批量生成,本地推理,人工智能声音克隆框架PaddleSpeech本地批量克隆实践(Python3.10)by Liu Yue/2023-06-15 标签: PaddleSpeech Python3.10 人工智能 克隆 声音 实践 批量 推理 本地 框架 生成 云端炼丹固然是极好的,但不能否认的是,成本要比本地高得多,同时考虑到深度学习的训练相对于推理来说成本也更高,这主要是因为它需要大量的数据、计算资源和时间等资源,并且对超参数的调整也要求较高,更适合在云端进行。 在推理阶段,模型的权重和参数不再调整。相反,模型根据输入数据的特征进行计算,并输出预测结果。推理阶段通常需要较少的计算资源和时间,所以训练我们可以放在云端,而批量推理环节完全可以挪到本地,这样更适合批量的声音克隆场景。 &n......了解更多
本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPTby Liu Yue/2023-03-24 标签: C++ ChatGPT LLaMA MacM1 单机 基于 推理 本地 模型 版本 系统 芯片 语言 运行 部署 OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿、130亿、330亿和650亿这4种参数规模的模型,参数是指神经网络中的权重和偏置等可调整的变量,用于训练和优化神经网络的性能,70亿意味着神经网络中有70亿个参数,由此类推。 在一些大型神经网络中,每个参数需要使用32位或64位浮点数进行存储,这意味着每个参数需要......了解更多