m4 mac mini本地部署ComfyUI,测试Flux-dev-GGUF的workflow模型10步出图,测试AI绘图性能,基于MPS(fp16),优点是能耗小和静音by Liu Yue/2024-12-09 标签: 10 ai ComfyUI dev Flux fp16 GGUF m4 Mac mini mps workflow 优点 本地 模型 步出 测试 绘图 能耗 静音 m4 mac mini已经发布了一段时间,针对这个产品,更多的是关于性价比的讨论,如果抛开各种补贴不论,价位上和以前发布的mini其实差别不大,真要论性价比,各种windows系统的mini主机的价格其实是吊打苹果的。 本次我们针对m4 mac mini的AI性能做个测试,使用目前泛用性最广的AI工作流软件:ComfyUI框架,基于MPS(fp16)模式进行测试。 Mac Os 本地部署ComfyUI &......了解更多
MagicQuill,AI动态图像元素修改,AI绘图,需要40G的本地硬盘空间,12G显存可玩,Win11本地部署by Liu Yue/2024-11-21 标签: 12G 40G ai MagicQuill Win11 修改 元素 动态 可玩 图像 显存 本地 硬盘空间 绘图 部署 需要 最近由 magic-quill 团队开源的 MagicQuill 项目十分引人瞩目,这个项目可以通过定制的 gradio 客户端针对不同的图像元素通过提示词进行修改,从而生成新的图像。值得一提的是,这个项目相当亲民,只需要20步迭代模型预测,甜品卡10秒钟就可以获取图片的修改效果,但是代价是至少需要40个G左右的磁盘空间。 本次分享一下如何在本地(Windows11)来部署MagicQuill项目。 首先需要下载依赖......了解更多
MaskGCT,AI语音克隆大模型本地部署(Windows11),基于Python3.11,TTS,文字转语音by Liu Yue/2024-10-28 标签: ai MaskGCT Python3.11 TTS Windows11 克隆 基于 文字 本地 模型 语音 部署 前几天,又一款非自回归的文字转语音的AI模型:MaskGCT,开放了源码,和同样非自回归的F5-TTS模型一样,MaskGCT模型也是基于10万小时数据集Emilia训练而来的,精通中英日韩法德6种语言的跨语种合成。数据集Emilia是全球最大且最为多样的高质量多语种语音数据集之一。 本次分享一下如何在本地部署MaskGCT项目,让您的显卡再次发烧。 安装基础依赖 首先确保本地已经安装好Py......了解更多
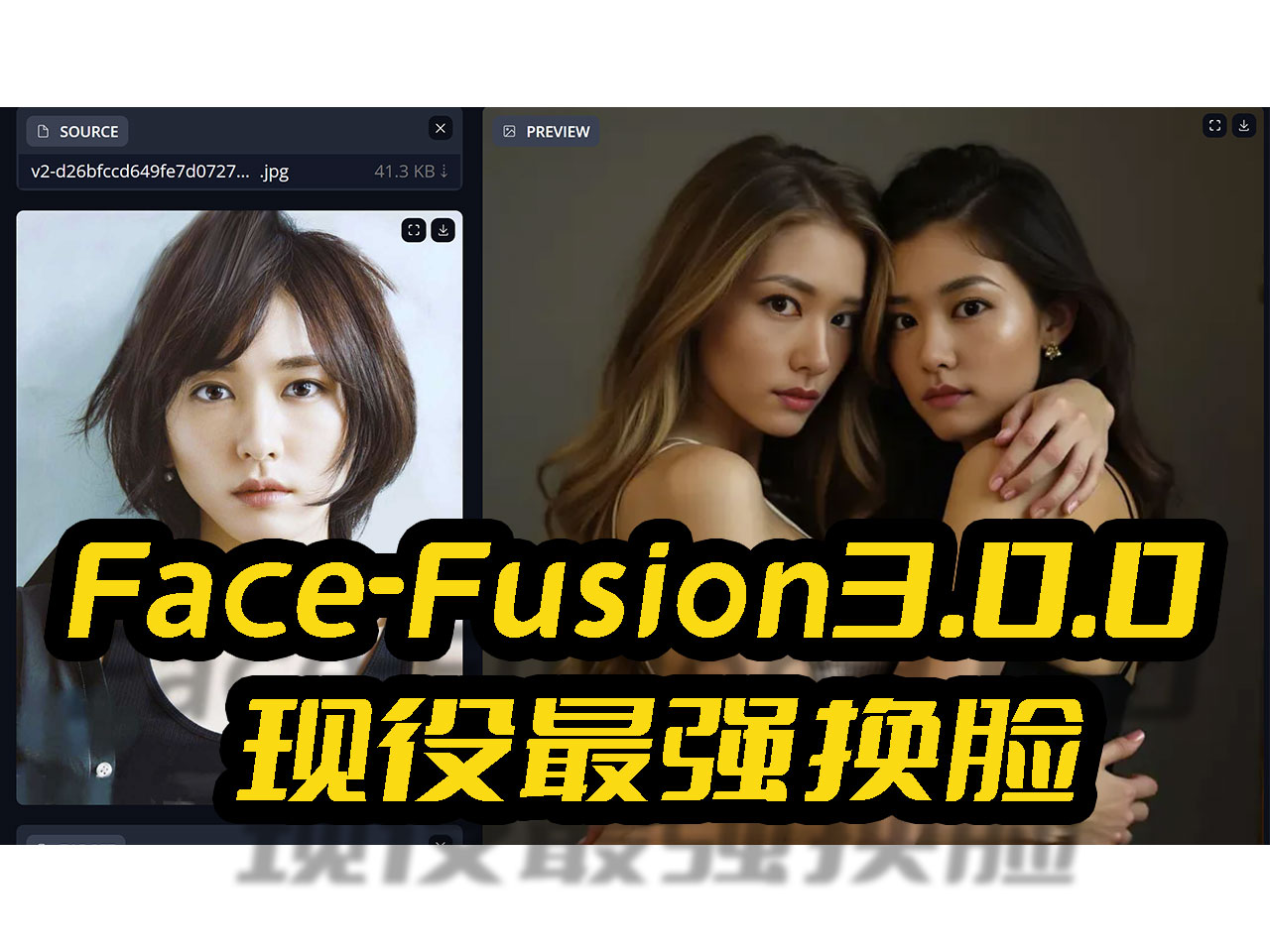
Win11本地部署FaceFusion3最强AI换脸,集成Tensorrt10.4推理加速,让甜品显卡也能发挥生产力by Liu Yue/2024-09-27 标签: ai FaceFusion3 Tensorrt10.4 Win11 加速 发挥 换脸 推理 显卡 最强 本地 甜品 生产力 部署 集成 FaceFusion3.0.0大抵是现在最强的AI换脸项目,分享一下如何在Win11系统,基于最新的cuda12.6配合最新的cudnn9.4本地部署FaceFusion3.0.0项目,并且搭配Tensorrt10.4,提高推理速度和效率,让甜品级显卡也能爆发生产力。 安装最新版本Cuda12.6以及Cudnn9.4 CUDA是NVIDIA公司开发的一种技术,它能让GPU像CPU一样编程,让GPU也能参与到计算中来,......了解更多
CosyVoice多语言、音色和情感控制模型,one-shot零样本语音克隆模型本地部署(Win/Mac),通义实验室开源by Liu Yue/2024-07-07 标签: CosyVoice Mac shot win 克隆 实验室 开源 情感 控制 本地 样本 模型 语言 语音 通义 部署 音色 近日,阿里通义实验室开源了CosyVoice语音模型,它支持自然语音生成,支持多语言、音色和情感控制,在多语言语音生成、零样本语音生成、跨语言声音合成和指令执行能力方面表现卓越。 CosyVoice采用了总共超15万小时的数据训练,支持中英日粤韩5种语言的合成,合成效果显著优于传统语音合成模型。 CosyVoice支持one-shot音色克隆 :仅需要3~10s的原始音频,即可生成模拟音色,甚至包括韵律、情感等细节。在......了解更多
OpenVoiceV2本地部署教程,苹果MacOs部署流程,声音响度统一,文字转语音,TTSby Liu Yue/2024-05-10 标签: MacOs OpenVoiceV2 TTS 响度 声音 教程 文字 本地 流程 统一 苹果 语音 部署 最近OpenVoice项目更新了V2版本,新的模型对于中文推理更加友好,音色也得到了一定的提升,本次分享一下如何在苹果的MacOs系统中本地部署OpenVoice的V2版本。 首先下载OpenVoiceV2的压缩包:OpenVoiceV2-for-mac代码和模型 https://pan.quark.cn/s/33dc06b46699 该版本针对MacOs系统做了一些优化,同时针对中文语音做了响度统一的修改。&nbs......了解更多
苹果AppleMacOs系统Sonoma本地部署无内容审查(NSFW)大语言量化模型Causallmby Liu Yue/2024-03-09 标签: AppleMacOs CausalLM NSFW Sonoma 内容 审查 本地 模型 系统 苹果 语言 部署 量化 最近Mac系统在运行大语言模型(LLMs)方面的性能已经得到了显著提升,尤其是随着苹果M系列芯片的不断迭代,本次我们在最新的MacOs系统Sonoma中本地部署无内容审查大语言量化模型Causallm。 这里推荐使用koboldcpp项目,它是由c++编写的kobold项目,而MacOS又是典型的Unix操作系统,自带clang编译器,也就是说MacOS操作系统是可以直接编译C语言的。 首先克隆koboldcpp项目......了解更多
无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14Bby Liu Yue/2024-02-28 标签: 14B CausalLM Win11 中文 内容 审查 无所不谈 本地 模型 百无禁忌 语言 部署 目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被“玩”坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt)来操纵LLM执行不当行为。内容审查可以帮助识别和过滤这些潜在的攻击,确保LLM按照既定的安全策略和道德标准运行。 但我们今天讨论的是无内容审查机制的大模型,在中文领域公开的模型中,能力相对比较强的有阿里的 Qwen-14B 和清华的 ChatGLM3-6B。 &n......了解更多
苹果AppleMacOs最新Sonoma系统本地训练和推理GPT-SoVITS模型实践by Liu Yue/2024-02-21 标签: AppleMacOs gpt Sonoma SoVITS 实践 推理 最新 本地 模型 系统 苹果 训练 GPT-SoVITS是少有的可以在MacOs系统下训练和推理的TTS项目,虽然在效率上没有办法和N卡设备相提并论,但终归是开发者在MacOs系统构建基于M系列芯片AI生态的第一步。 环境搭建 首先要确保本地环境已经安装好版本大于6.1的FFMPEG软件:(base) ➜ ~ ffmpeg -versionffmpeg version 6.1.1 Copyright (c) 2000-2023 the FFmpeg ......了解更多
如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Faceby Liu Yue/2024-01-15 标签: Bert Face Hugging vits2 如何 快速 本地 模型 训练 语音 部署 Hugging Face是一个机器学习(ML)和数据科学平台和社区,帮助用户构建、部署和训练机器学习模型。它提供基础设施,用于在实时应用中演示、运行和部署人工智能(AI)。用户还可以浏览其他用户上传的模型和数据集。Hugging Face通常被称为机器学习界的GitHub,因为它让开发人员公开分享和测试他们所训练的模型。 本次分享如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face。 本......了解更多
Bert-vits2-v2.2新版本本地训练推理整合包(原神八重神子英文模型miko)by Liu Yue/2023-12-18 标签: Bert miko v2.2 vits2 八重 原神 推理 整合 本地 模型 版本 神子 英文 训练 近日,Bert-vits2-v2.2如约更新,该新版本v2.2主要把Emotion 模型换用CLAP多模态模型,推理支持输入text prompt提示词和audio prompt提示语音来进行引导风格化合成,让推理音色更具情感特色,并且推出了新的预处理webuI,操作上更加亲民和接地气。 更多情报请参见Bert-vits2官网:https://github.com/fishaudio/Bert-VITS2/releases/tag/v2.2&......了解更多
Bert-vits2新版本V2.1英文模型本地训练以及中英文混合推理(mix)by Liu Yue/2023-12-08 标签: Bert mix V2.1 vits2 中英文 以及 推理 本地 模型 混合 版本 英文 训练 中英文混合输出是文本转语音(TTS)项目中很常见的需求场景,尤其在技术文章或者技术视频领域里,其中文文本中一定会夹杂着海量的英文单词,我们当然不希望AI口播只会念中文,Bert-vits2老版本(2.0以下版本)并不支持英文训练和推理,但更新了底模之后,V2.0以上版本支持了中英文混合推理(mix)模式。 还是以霉霉为例子:https://www.bilibili.com/video/BV1bB4y1R7Nu/ 截取......了解更多
本地训练,立等可取,30秒音频素材复刻霉霉讲中文音色基于Bert-VITS2V2.0.2by Liu Yue/2023-11-27 标签: 30 Bert vits2V2.0 中文 基于 复刻 本地 立等可取 素材 训练 霉霉 音色 音频 之前我们使用Bert-VITS2V2.0.2版本对现有的原神数据集进行了本地训练,但如果克隆对象脱离了原神角色,我们就需要自己构建数据集了,事实上,深度学习模型的性能和泛化能力都依托于所使用的数据集的质量和多样性,本次我们在本地利用Bert-VITS2V2.0.2对霉霉讲中文的音色进行克隆实践。 霉霉讲中文的原始音视频地址:https://www.bilibili.com/video/BV1bB4y1R7Nu/ &nb......了解更多
本地训练,开箱可用,Bert-VITS2 V2.0.2版本本地基于现有数据集训练(原神刻晴)by Liu Yue/2023-11-22 标签: Bert V2.0 vits2 原神刻 可用 基于 开箱 数据 本地 版本 现有 训练 按照固有思维方式,深度学习的训练环节应该在云端,毕竟本地硬件条件有限。但事实上,在语音识别和自然语言处理层面,即使相对较少的数据量也可以训练出高性能的模型,对于预算有限的同学们来说,也没必要花冤枉钱上“云端”了,本次我们来演示如何在本地训练Bert-VITS2 V2.0.2模型。 Bert-VITS2 V2.0.2基于现有数据集 目前Bert-VITS2 V2.0.2大体上有两种训练方式,第一种是基于现有数据集,即原......了解更多
批量生成,本地推理,人工智能声音克隆框架PaddleSpeech本地批量克隆实践(Python3.10)by Liu Yue/2023-06-15 标签: PaddleSpeech Python3.10 人工智能 克隆 声音 实践 批量 推理 本地 框架 生成 云端炼丹固然是极好的,但不能否认的是,成本要比本地高得多,同时考虑到深度学习的训练相对于推理来说成本也更高,这主要是因为它需要大量的数据、计算资源和时间等资源,并且对超参数的调整也要求较高,更适合在云端进行。 在推理阶段,模型的权重和参数不再调整。相反,模型根据输入数据的特征进行计算,并输出预测结果。推理阶段通常需要较少的计算资源和时间,所以训练我们可以放在云端,而批量推理环节完全可以挪到本地,这样更适合批量的声音克隆场景。 &n......了解更多
Python3.10动态修改Windows系统(win10/win11)本地IP地址(静态IP)by Liu Yue/2023-05-09 标签: IP IP地址 Python3.10 win10 Win11 Windows 修改 动态 本地 系统 静态 一般情况下,局域网里的终端比如本地服务器设置静态IP的好处是可以有效减少网络连接时间,原因是过程中省略了每次联网后从DHCP服务器获取IP地址的流程,缺点是容易引发IP地址的冲突,当然,还有操作层面的繁琐,如果想要切换静态IP地址,就得去网络连接设置中手动操作,本次我们使用Python3.10动态地修改电脑的静态IP地址。 获取多网卡配置 一个网卡对应一个静态IP地址,但机器上未必只有一个网卡,所以如果想动态切换,必......了解更多
本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPTby Liu Yue/2023-03-24 标签: C++ ChatGPT LLaMA MacM1 单机 基于 推理 本地 模型 版本 系统 芯片 语言 运行 部署 OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿、130亿、330亿和650亿这4种参数规模的模型,参数是指神经网络中的权重和偏置等可调整的变量,用于训练和优化神经网络的性能,70亿意味着神经网络中有70亿个参数,由此类推。 在一些大型神经网络中,每个参数需要使用32位或64位浮点数进行存储,这意味着每个参数需要......了解更多
闻其声而知雅意,M1 Mac基于PyTorch(mps/cpu/cuda)的人工智能AI本地语音识别库Whisper(Python3.10)by Liu Yue/2023-01-17 标签: ai CPU cuda M1 Mac mps Python3.10 Pytorch Whisper 人工智能 基于 本地 而知 识别 语音 闻其声 雅意 前文回溯,之前一篇:含辞未吐,声若幽兰,史上最强免费人工智能AI语音合成TTS服务微软Azure(Python3.10接入),利用AI技术将文本合成语音,现在反过来,利用开源库Whisper再将语音转回文字,所谓闻其声而知雅意。 Whisper 是一个开源的语音识别库,它是由Facebook AI Research (FAIR)开发的,支持多种语言的语音识别。它使用了双向循环神经网络(bi-directional RNNs)来识别语音并将其转......了解更多
利用本地HTTPS模拟环境为FastAPI框架集成FaceBook社交三方登录by Liu Yue/2020-09-06 标签: FaceBook FastAPI https 三方 利用 本地 框架 模拟 环境 登录 社交 集成 提起社交,就不得不说马克·扎克伯格(Mark Zuckerberg)一手创办的社交网络(FaceBook)。进入2020年,FaceBook的全球用户数已经突破了30亿,这是什么概念?全球人口大约70亿,除开中国14亿,还有56亿。国外市场是四倍于中国的潜在市场,扣除短期内有上网限制的人群,那也是两倍以上。站在全球视角看问题,说微信、支付宝偏安一隅,其实也并不为过。所以为你的平台集成全球最大用户基数的社交登录系统,显然可以为你带来更多的潜在用户,本次我们使用当红炸子鸡......了解更多