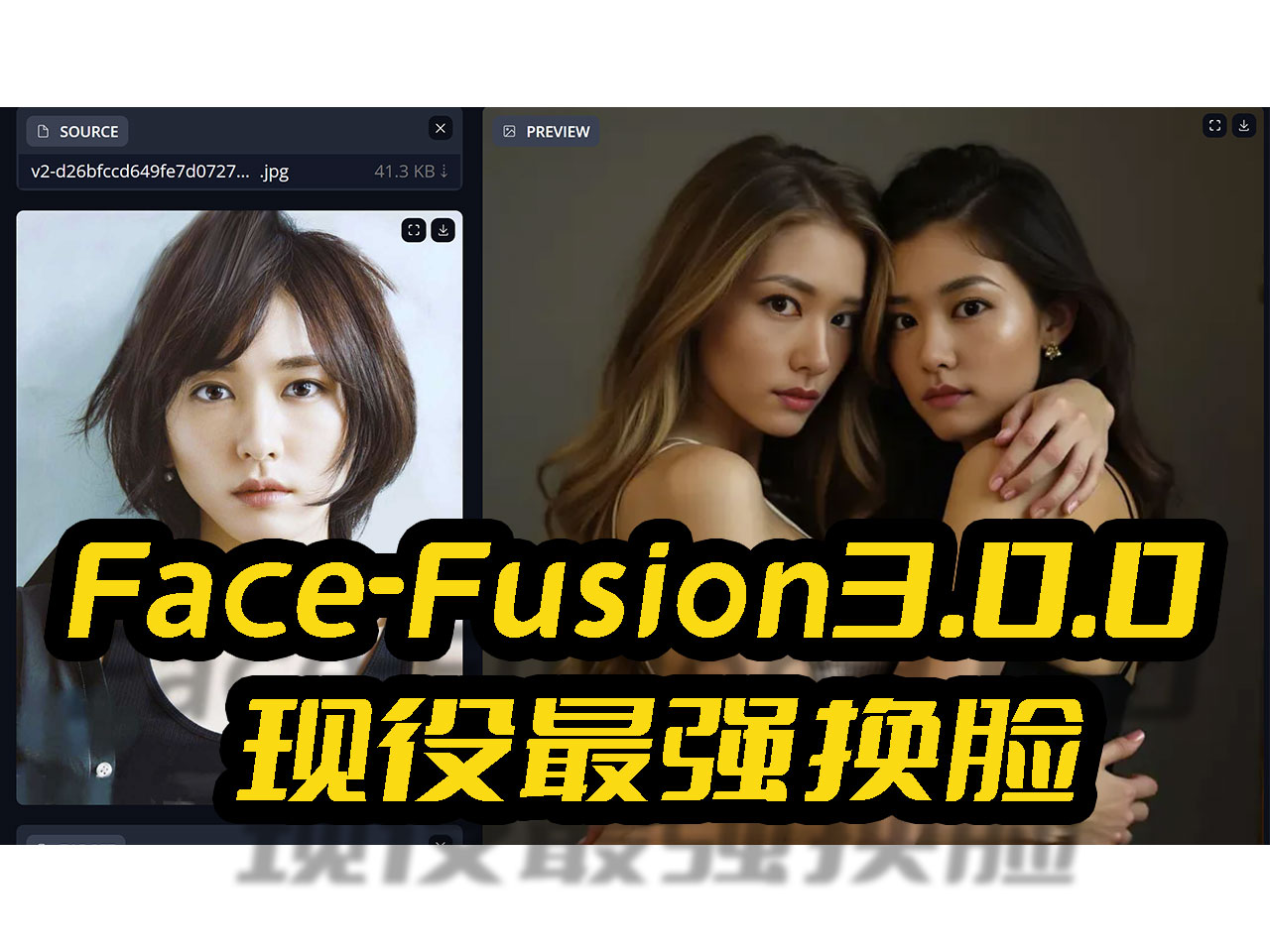
使用腾讯混元(HunYuanVideo)视频模型FP8量化版本来生成绅士动画,模型体积30G,8G甜品卡可玩,2秒视频需要15分钟
腾讯混元(HunYuanVideo)视频模型发布以来,视频效果有口皆碑,但由于推理门槛比较高,消费级显卡用户望而却步,最近大神Kijai发布了FP8量化版本模型,使得甜品卡用户也有了一餐秀色的可能。 本次我们利用HunYuanVideo量化版模型来生成绅士视频。 本地部署ComfyUI 首先需要本地部署ComfyUI框架,克隆官方项目:git clone https://github.com......