GPT-SoVITS教程,接入酒馆AI,SillyTavern-1.11.5,让AI女友声若幽兰

本次分享一下如何将GPT-SoVITS接入SillyTavern-1.11.5项目,让让AI女友声若幽兰,首先明确一下,SillyTavern-1.11.5只是一个前端项目,它没有任何大模型文本生成能力,所以后端必须有一个api服务来流式生成对话文本,这里选择koboldcpp。
首先看一下简单的项目运行架构图:
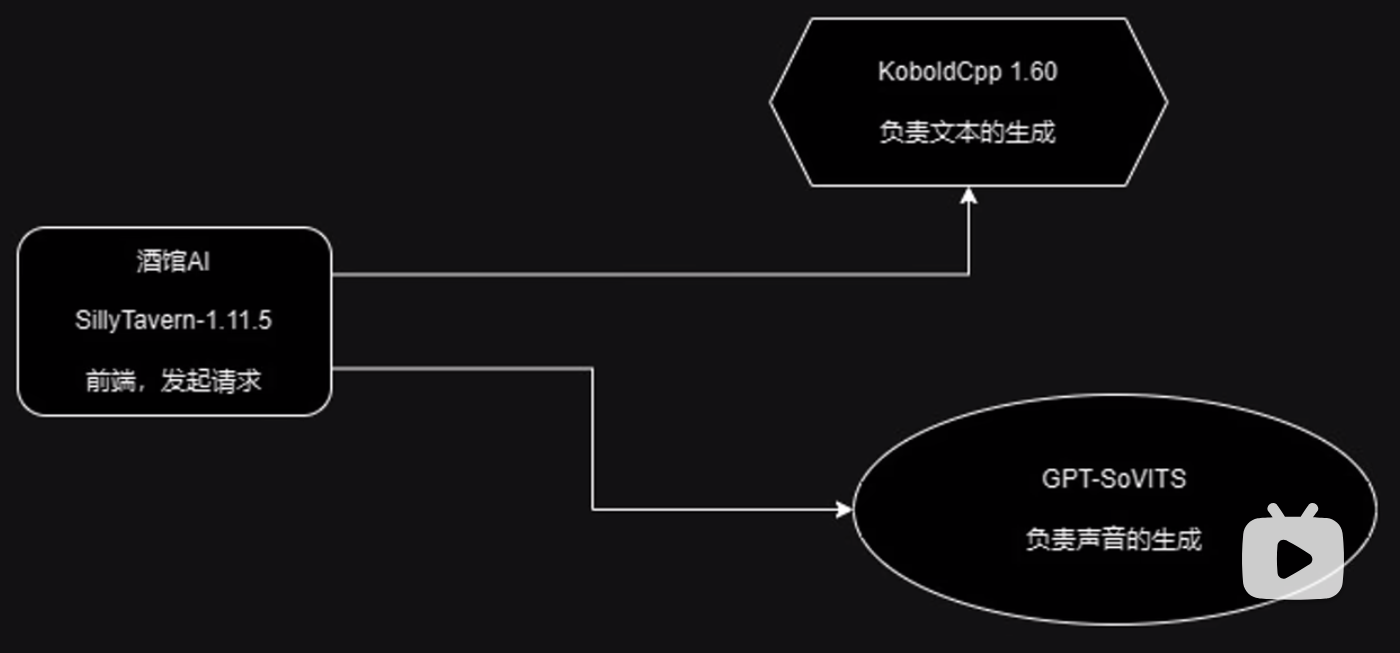
这里SillyTavern作为前端负责向后端的Koboldcpp发起请求,Koboldcpp流式返回文本,SillyTavern接受聊天文本进行展示,当文本接受完毕后,SillyTavern再次向后端的GPT-SoVITS发起请求,将全量文本传递给后端GPT-SoVITS,GPT-SoVITS根据文字来生成语音,并将语音的二进制文件返回给SillyTavern,最后SillyTavern播放音频,至此,一个完整的流程就走完了。
部署SillyTavern
首先克隆SillyTavern的官方项目:
git clone https://github.com/SillyTavern/SillyTavern.git 直接运行启动脚本即可:
shell start.sh 如果是windows平台,运行bat:
start.bat 由于SillyTavern没有预留GPT-SoVITS的位置,所有将原本的XTTS改为GPT-SoVITS:
async fetchTtsGeneration(inputText, voiceId) {
console.info(`Generating new TTS for voice_id ${voiceId}`);
if (this.settings.streaming) {
const params = new URLSearchParams();
params.append('text', inputText);
params.append('speaker_wav', voiceId);
params.append('language', this.settings.language);
return `${this.settings.provider_endpoint}/tts_stream/?${params.toString()}`;
}
const response = await doExtrasFetch(
`${this.settings.provider_endpoint}/tts_to_audio/`,
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Cache-Control': 'no-cache', // Added this line to disable caching of file so new files are always played - Rolyat 7/7/23
},
body: JSON.stringify({
'text': inputText,
'speaker_wav': voiceId,
'language': this.settings.language,
}),
},
);
if (!response.ok) {
toastr.error(response.statusText, 'TTS Generation Failed');
throw new Error(`HTTP ${response.status}: ${await response.text()}`);
}
return response;
}部署Koboldcpp
随后部署后端的大模型api:
git clone https://github.com/LostRuins/koboldcpp.git输入编译命令
windows平台:
make Mac平台:
make LLAMA_METAL=1 安装依赖:
pip install -r requirements.txt 启动服务:
Python3 koboldcpp.py --model /Users/liuyue/Downloads/causallm_7b-dpo-alpha.Q5_K_M.gguf --gpulayers 40 --highpriority --threads 300 此时接口运行在http://localhost:5001
部署GPT-SoVITS
最后,部署GPT-SoVITS项目:
git clone https://github.com/RVC-Boss/GPT-SoVITS.git 安装依赖:
pip3 install -r requirements.txt 修改一下api接口逻辑:
@app.post("/")
async def tts_endpoint(request: Request):
json_post_raw = await request.json()
return handle(
json_post_raw.get("refer_wav_path"),
json_post_raw.get("prompt_text"),
json_post_raw.get("prompt_language"),
json_post_raw.get("text"),
json_post_raw.get("text_language"),
json_post_raw.get("sweight"),
json_post_raw.get("gweight"),
)
@app.get("/")
async def tts_endpoint(
refer_wav_path: str = None,
prompt_text: str = None,
prompt_language: str = None,
text: str = None,
text_language: str = None,
sweight: str = None,
gweight: str = None,
):
return handle(refer_wav_path, prompt_text, prompt_language, text, text_language,sweight,gweight)
def speaker_handle():
return JSONResponse(["female_calm","female","male"], status_code=200)
@app.get("/speakers_list")
async def speakerlist_endpoint():
return speaker_handle()
def tts_to_audio_handle(text):
return handle(llama_audio,llama_text,llama_lang,text,"中英混合")
@app.post("/tts_to_audio/")
async def tts_to_audio(request: Request):
json_post_raw = await request.json()
return tts_to_audio_handle(json_post_raw.get("text"))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=port, workers=1) 这里添加新的基于get方法的speakers_list,是为了配合xtts接口的格式,同时基于post方法的tts_to_audio方法用来生成语音,它只接受一个参数text,也就是需要转为语音的文本。
至此,三个服务就都配置好了,最后奉上视频教程:
https://www.bilibili.com/video/BV1uJ4m1a7L4/