搞清楚系统到底怎样支撑高并发以及架构图的绘制(面试向)
大多数人面试的时候经常会被问到:你简历上有高负载高并发的经验,那到底你的系统是怎样设计的?
如果没有过相关的项目经验,大多数同学被问到这个问题压根儿没什么思路去回答,不知道从什么地方说起,其实,就算没有相关的经验,只要事先编好话术,搞清楚架构图,回答此类问题也还是可以滴水不漏的。
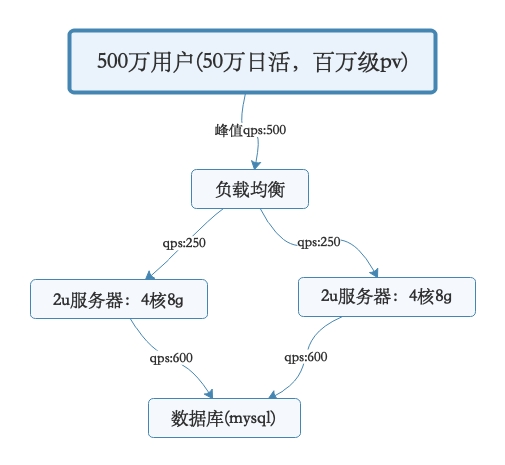
首先,在脑子里虚拟一个大用户量背景下的场景,如果我们手头有几台4核8g的服务器,假设一个平台用户量是500万。此时日活用户是50万,日访问量在600-700万左右,高峰期对系统每秒请求是500/s。然后对数据库的每秒请求数量是1500/s,这个时候会怎么样呢?如果系统内处理的是较为复杂的一些业务逻辑,是那种重业务逻辑的系统的话,是比较耗费CPU的。此时,4核8G的机器每秒请求达到500/s的时候,很可能你的机器CPU负载较高了。然后数据库层面,以上述的配置而言,其实基本上1500/s的高峰请求压力的话,还算可以接受。这个主要是要观察数据库所在机器的磁盘负载、网络负载、CPU负载、内存负载,按照我们的线上经验而言,那个配置的数据库在1500/s请求压力下是没问题的。所以此时需要做的一个事情,首先就是要支持你的系统集群化部署。可以在前面挂一个负载均衡层,把请求均匀打到系统层面,让系统可以用多台机器集群化支撑更高的并发压力。比如说这里假设给系统增加部署一台机器,那么每台机器就只有250/s的请求了。这样一来,两台机器的CPU负载都会明显降低,这个初步的“高并发”不就先抗住住了吗?要是连这个都不做,那单台机器负载越来越高的时候,极端情况下是可能出现机器上部署的系统无法有足够的资源响应请求了,然后出现请求卡死,甚至系统宕机之类的问题。所以,简单小结,第一步要做的:添加负载均衡层,将请求均匀打到系统层。系统层采用集群化部署多台机器,扛住初步的并发压力。
架构图如下:
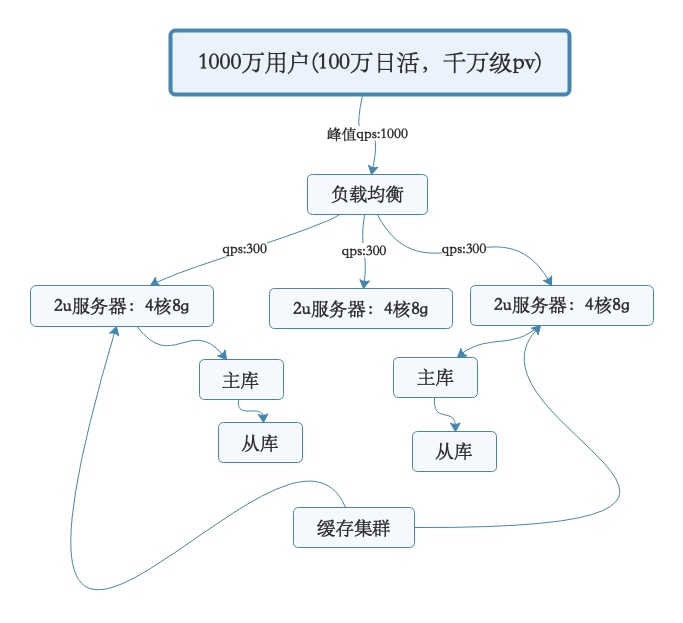
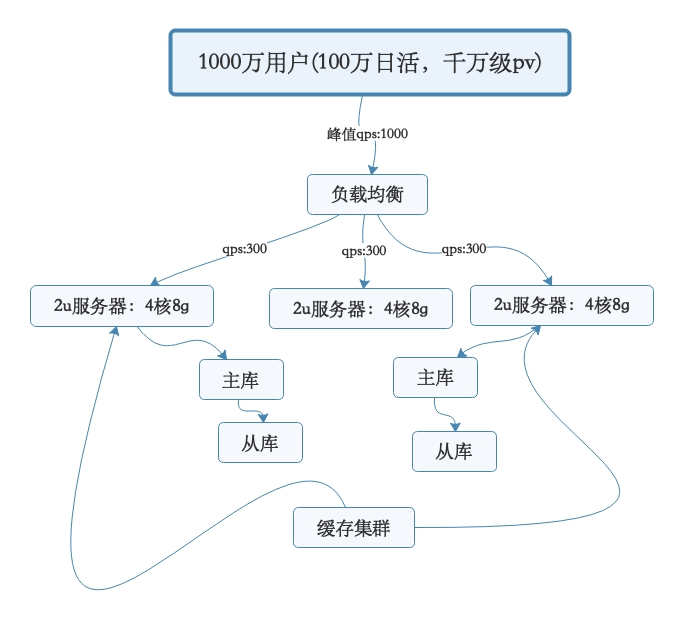
然后,经过了几个月的增长期,假设此时用户量继续增长,达到了1000万注册用户,然后每天日活用户是100万,日访问量在800-1000万。那么此时对系统层面的请求量会达到每秒1000/s,系统层面,你可以继续通过集群化的方式来扩容,反正前面的负载均衡层会均匀分散流量过去的。但是,这时数据库层面接受的请求量会达到3000/s,这个就有点问题了。此时数据库层面的并发请求翻了一倍,你一定会发现线上的数据库负载越来越高。每次到了高峰期,磁盘IO、网络IO、内存消耗、CPU负载的压力都会很高,大家很担心数据库服务器能否抗住。没错,一般来说,对那种普通配置的线上数据库,建议就是读写并发加起来,按照上述我们举例的那个配置,不要超过3000/s。因为数据库压力过大,首先一个问题就是高峰期系统性能可能会降低,因为数据库负载过高对性能会有影响。另外一个,压力过大把你的数据库给搞挂了怎么办?所以此时你必须得对系统做分库分表 + 读写分离,也就是把一个库拆分为多个库,部署在多个数据库服务上,这是作为主库承载写入请求的。然后每个主库都挂载至少一个从库,由从库来承载读请求。此时假设对数据库层面的读写并发是3000/s,其中写并发占到了1000/s,读并发占到了2000/s。那么一旦分库分表之后,采用两台数据库服务器上部署主库来支撑写请求,每台服务器承载的写并发就是500/s。每台主库挂载一个服务器部署从库,那么2个从库每个从库支撑的读并发就是1000/s。简单总结,并发量继续增长时,我们就需要专注在数据库层面:分库分表、读写分离。
如果注册用户量越来越大,此时你可以不停地加机器,比如说系统层面不停加机器,就可以承载更高的并发请求。然后数据库层面如果写入并发越来越高,就扩容加数据库服务器,通过分库分表是可以支持扩容机器的,如果数据库层面的读并发越来越高,就扩容加更多的从库。但是这里有一个很大的问题:数据库其实本身不是用来承载高并发请求的。所以通常来说,数据库单机每秒承载的并发就在几千的数量级,而且数据库使用的机器都是比较高配置,比较昂贵的机器,成本很高。如果不停地加机器,这是不对的。在高并发架构里通常都有缓存这个环节,缓存系统的设计就是为了承载高并发而生。单机承载的并发量都在每秒几万,甚至每秒数十万,对高并发的承载能力比数据库系统要高出一到两个数量级。可以根据系统的业务特性,对那种写少读多的请求,引入缓存集群。具体来说,就是在写数据库的时候同时写一份数据到缓存集群里,然后用缓存集群来承载大部分的读请求。这样的话,通过缓存集群,就可以用更少的机器资源承载更高的并发。比如说上面那个图里,读请求目前是每秒1000/s,两个从库各自抗了500/s读请求,但是其中可能每秒800次的读请求都是可以直接读缓存里的不怎么变化的数据的。那么此时你一旦引入缓存集群,就可以抗下来这800/s读请求,落到数据库层面的读请求就200/s。
架构图如下:
初步来说,简单的一个高并发系统的阐述是说完了,是不是很简单呢?
- Next Post使用python将word文档和pdf电子书进行格式互转(兼容Windows/Linux)
- Previous Post使用Hexo建立一个轻量、简易、高逼格的博客