AI天后,在线飙歌,人工智能AI孙燕姿模型应用实践,复刻《遥远的歌》,原唱晴子(Python3.10)

忽如一夜春风来,亚洲天后孙燕姿独特而柔美的音色再度响彻华语乐坛,只不过这一次,不是因为她出了新专辑,而是人工智能AI技术对于孙燕姿音色的完美复刻,以大江灌浪之势对华语歌坛诸多经典作品进行了翻唱,还原度令人咋舌,如何做到的?
本次我们借助基于Python3.10的开源库so-vits-svc,让亚洲天后孙燕姿帮我们免费演唱喜欢的歌曲,实现点歌自由。
so-vits-svc是基于VITS的开源项目,VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。
VITS通过隐变量而非频谱串联起来语音合成中的声学模型和声码器,在隐变量上进行随机建模并利用随机时长预测器,提高了合成语音的多样性,输入同样的文本,能够合成不同声调和韵律的语音。
环境配置
首先确保本机已经安装好Python3.10的开发环境,随后使用Git命令克隆项目:
git clone https://github.com/svc-develop-team/so-vits-svc.git随后进入项目的目录:
cd so-vits-svc接着安装依赖,如果是Linux或者Mac系统,运行命令:
pip install -r requirements.txt 如果是Windows用户,需要使用Win系统专用的依赖文件:
pip install -r requirements_win.txt 依赖库安装成功之后,在项目的根目录运行命令,启动服务:
python webUI.py 程序返回:
PS D:\so-vits-svc> python .\webUI.py
DEBUG:charset_normalizer:Encoding detection: ascii is most likely the one.
C:\Users\zcxey\AppData\Roaming\Python\Python310\site-packages\gradio\deprecation.py:43: UserWarning: You have unused kwarg parameters in UploadButton, please remove them: {'variant': 'primary'}
warnings.warn(
DEBUG:asyncio:Using proactor: IocpProactor
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`. 说明服务已经正常启动了,这里so-vits-svc会在后台运行一个基于Flask框架的web服务,端口号是7860,此时访问本地的网址:127.0.0.1:7860:
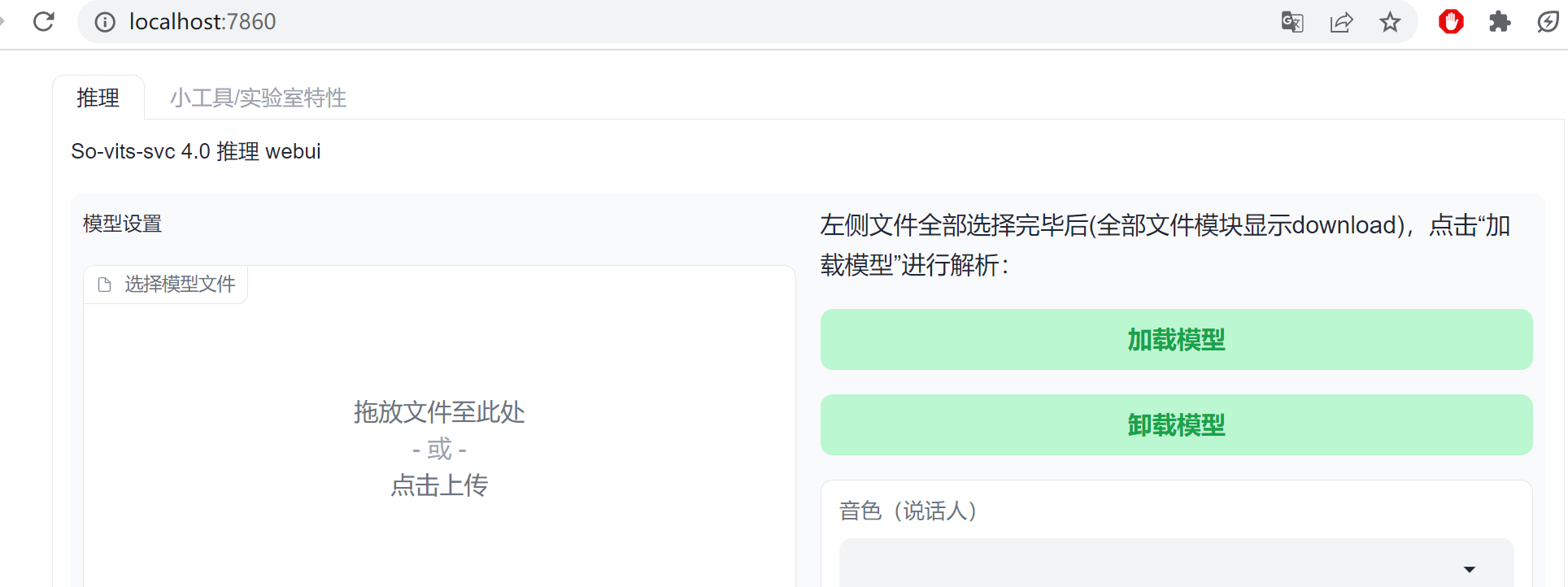
此时,我们就可以加载模型,模型训练先按下不表,这里先使用已经训练好的孙燕姿音色模型:
链接:https://pan.baidu.com/s/1RwgRe6s4HCA2eNI5sxHZ9A?pwd=7b4a
提取码:7b4a 下载模型文件之后,将模型文件放入logs/44k目录:
D:\so-vits-svc\logs\44k>dir
驱动器 D 中的卷是 新加卷
卷的序列号是 9824-5798
D:\so-vits-svc\logs\44k 的目录
2023/05/10 12:31 <DIR> .
2023/05/10 11:49 <DIR> ..
2023/04/08 15:22 542,178,141 G_27200.pth
2023/04/08 15:54 15,433,721 kmeans_10000.pt
2023/05/10 11:49 0 put_pretrained_model_here
3 个文件 557,611,862 字节
2 个目录 475,872,493,568 可用字节
D:\so-vits-svc\logs\44k> 接着将模型的配置文件config.js放入configs目录:
D:\so-vits-svc\configs>dir
驱动器 D 中的卷是 新加卷
卷的序列号是 9824-5798
D:\so-vits-svc\configs 的目录
2023/05/10 11:49 <DIR> .
2023/05/10 12:23 <DIR> ..
2023/04/08 12:33 2,118 config.json
1 个文件 2,118 字节
2 个目录 475,872,493,568 可用字节
D:\so-vits-svc\configs> 随后,在页面中点击加载模型即可,这里环境就配置好了。
原始歌曲处理(人声和伴奏分离)
如果想要使用孙燕姿的模型进行推理,让孙燕姿同学唱别的歌手的歌,首先需要一段已经准备好的声音范本,然后使用模型把原来的音色换成孙燕姿模型训练好的音色,有些类似Stable-Diffusion的图像风格迁移,只不过是将绘画风格替换为音色和音准。
这里我们使用晴子的《遥远的歌》,这首歌曲调悠扬,如诉如泣,和孙燕姿婉转的音色正好匹配。好吧,其实是因为这首歌比较简单,方便新手练习。
需要注意的是,模型推理过程中,需要的歌曲样本不应该包含伴奏,因为伴奏属于“噪音”,会影响模型的推理效果,因为我们替换的是歌手的“声音”,并非伴奏。
这里我们选择使用开源库Spleeter来对原歌曲进行人声和伴奏分离,首先安装spleeter:
pip3 install spleeter --user接着运行命令,对《遥远的歌》进行分离操作:
spleeter separate -o d:/output/ -p spleeter:2stems d:/遥远的歌.mp3这里-o代表输出目录,-p代表选择的分离模型,最后是要分离的素材。
首次运行会比较慢,因为spleeter会下载预训练模型,体积在1.73g左右,运行完毕后,会在输出目录生成分离后的音轨文件:
C:\Users\zcxey\Downloads\test>dir
驱动器 C 中的卷是 Windows
卷的序列号是 5607-6354
C:\Users\zcxey\Downloads\test 的目录
2023/05/09 13:17 <DIR> .
2023/05/10 20:57 <DIR> ..
2023/05/09 13:17 26,989,322 accompaniment.wav
2023/05/09 13:17 26,989,322 vocals.wav
2 个文件 53,978,644 字节
2 个目录 182,549,413,888 可用字节 其中vocals.wav为晴子的清唱声音,而accompaniment.wav则为伴奏。
关于spleeter更多的操作,请移步至:人工智能AI库Spleeter免费人声和背景音乐分离实践(Python3.10) , 这里不再赘述。
至此,原始歌曲就处理好了。
歌曲推理
此时,将晴子的清唱声音vocals.wav文件添加到页面中:
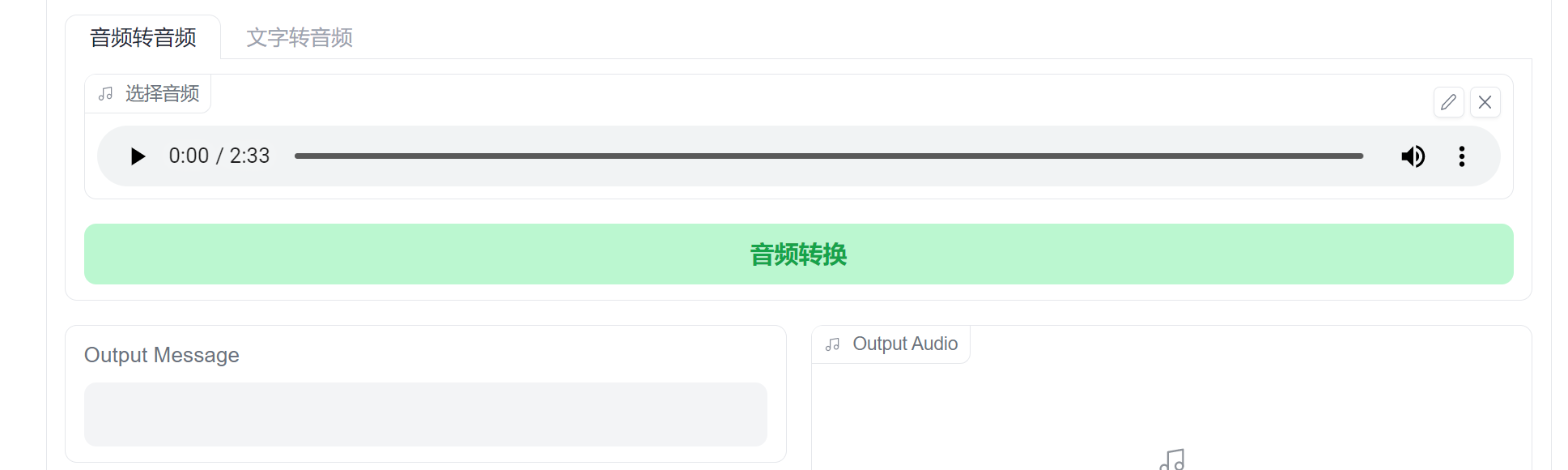
接着就是参数的调整:
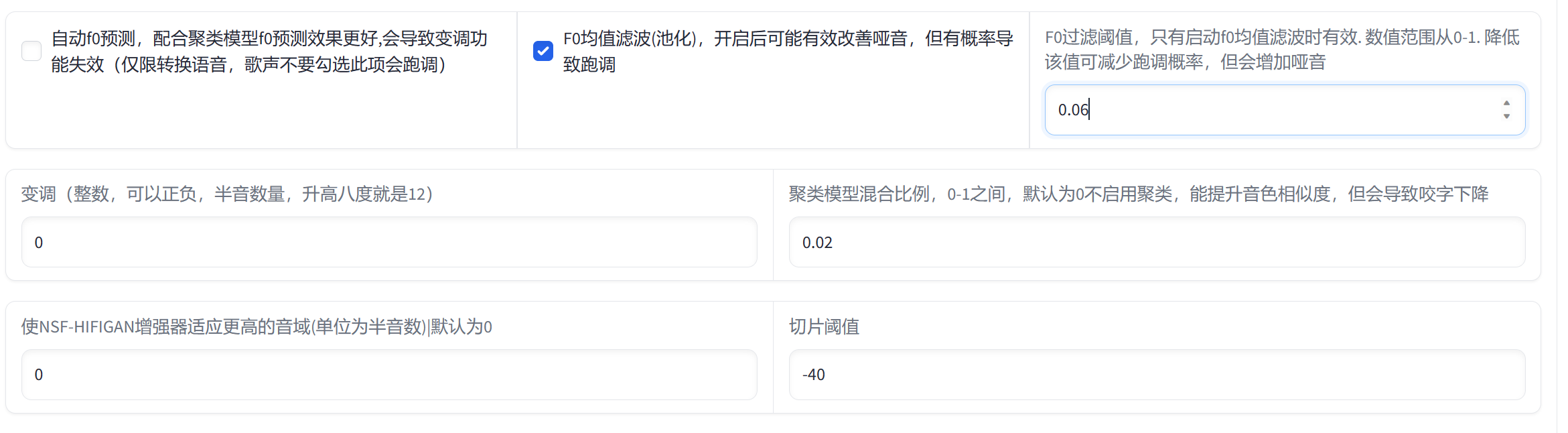
这里推理歌曲会有两个问题,就是声音沙哑和跑调,二者必居其一。
F0均值滤波(池化)参数开启后可以有效改善沙哑问题,但有概率导致跑调,而降低该值则可以减少跑调的概率,但又会出现声音沙哑的问题。
基本上,推理过程就是在这两个参数之间不断地调整。
所以每一次推理都需要认真的听一下歌曲有什么问题,然后调整参数的值,这里我最终的参数调整结果如上图所示。
推理出来的歌曲同样也是wav格式,此时我们将推理的清唱声音和之前分离出来的伴奏音乐accompaniment.wav进行合并即可,这里推荐使用FFMPEG:
ffmpeg -f concat -i <( for f in *.wav; do echo "file '$(pwd)/$f'"; done ) output.wav 该命令可以把推理的人声wav和背景音乐wav合并为一个output.wav歌曲,也就是我们最终的作品。
结语
藉此,我们就完成了自由点歌让天后演唱的任务,如果后期配上画面和歌词的字幕,不失为一个精美的AI艺术品,在Youtube(B站)搜索关键字:刘悦的技术博客,即可欣赏最终的成品歌曲,欢迎诸君品鉴。