浩若烟海事半功倍|利用Docker容器技术构建自动化分布式web测试集群Selenium Gridby Liu Yue/2021-06-27 标签: Docker Grid Selenium Web 事半功倍 分布式 利用 容器 技术 构建 测试 浩若 烟海 自动化 集群 “世界上有那么多城市,城市里有那么多的酒馆,可她,却偏偏走进了我的.....”,这是电影《卡萨布拉卡》中的一句著名独白,投射到现实生活中,与之类似的情况不胜枚举,这世界上有那么多的系统,系统中有那么多的浏览器,在只有一台测试机的前提下,难道我们只能排队一个一个地做兼容性测试吗?有没有效率更高的方法呢?为此我们提出一个更高效的解决方案:使用Docker+Selenium Grid。 Selenium Grid是一个分布式WebUI测试工具,可以......了解更多
说起分布式自增ID只知道UUID?SnowFlake(雪花)算法了解一下(Python3.0实现)by Liu Yue/2020-06-11 标签: ID Python3.0 SnowFlake UUID 一下 了解 分布式 实现 知道 算法 自增 说起 雪花 但凡说起分布式系统,我们肯定会对一些海量级的业务进行分拆,比如:用户表,订单表。因为数据量巨大一张表完全无法支撑,就会对其进行分库分表。但是一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题,当我们使用mysql的自增长主键(auto_increment)时,充分感受到了它的好处:整个系统ID唯一,ID是数字类型,而且是趋势递增的,ID简短,查询效率快,在分布式系统中显然由于单点问题无法使用mysql自增长了,此时需要别的解决方案来支撑分布式业务。&nb......了解更多
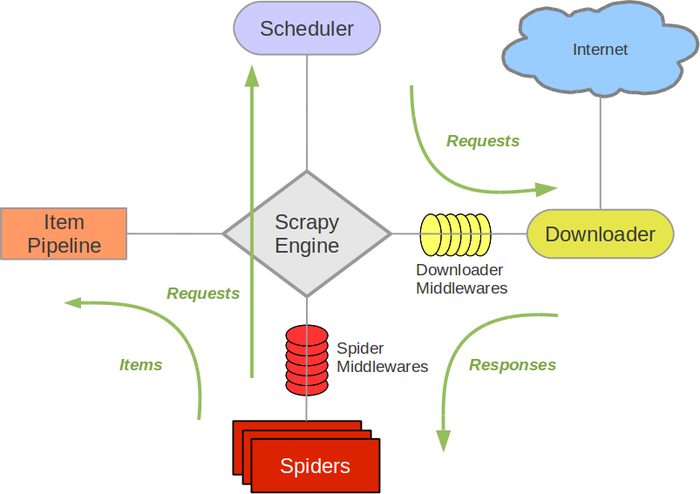
在阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redisby Liu Yue/2019-05-27 标签: 爬虫 Scrapy 阿里 基于 redis 部署 Centos7.6 分布式 上面 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(......了解更多