基于Python3(Autosub)以及Ffmpeg配合GoogleTranslation(谷歌翻译)为你的影片实现双语版字幕(逐字稿)

为影片加字幕其实是一件非常耗费时间的事情,尤其是对于打字慢的朋友来说。当然不光为影片加字幕,在其他领域,类似的逐字稿也是工作中避免不了的内容。比如写论文,如果内容中有访谈,就必须要附上逐字稿,又或者是会议的记录等等。本次使用基于Python3的AutoSub库对实时语音进行识别,然后再通过GoogleTranslation的在线API接口对语音识别后的内容进行翻译,这样就可以得到一份双语字幕(逐字稿),这里的双语不只针对国语+英语组合,也可以包含其他国家,包括小语种地区,非常方便。
首先需要安装ffmpeg,这个软件在之前有过介绍:Python3利用ffmpeg针对视频进行一些操作,Win10用户可以根据这篇文章进行安装,如果是Mac用户则非常简单,使用Homebrew就可以非常方便的进行安装
brew install ffmpeg其后安装autosub,这个库其实就是针对Google的语音识别封装而成的,最早基于Python2,近几年也出现很多“魔改版”,这里推荐尽量安装原版的基于Python3的最新版,而使用pip直接install往往无法安装最新版,所以这里推荐用git版本库地址的方式进行安装,这样可以避免很多坑:
pip3 install git+https://github.com/agermanidis/autosub.git安装成功后,输入命令:
autosub -h就可以看到使用说明:
liuyue:myr liuyue$ autosub -h
usage: autosub [-h] [-C CONCURRENCY] [-o OUTPUT] [-F FORMAT] [-S SRC_LANGUAGE]
[-D DST_LANGUAGE] [-K API_KEY] [--list-formats]
[--list-languages]
[source_path]
positional arguments:
source_path Path to the video or audio file to subtitle
optional arguments:
-h, --help show this help message and exit
-C CONCURRENCY, --concurrency CONCURRENCY
Number of concurrent API requests to make
-o OUTPUT, --output OUTPUT
Output path for subtitles (by default, subtitles are
saved in the same directory and name as the source
path)
-F FORMAT, --format FORMAT
Destination subtitle format
-S SRC_LANGUAGE, --src-language SRC_LANGUAGE
Language spoken in source file
-D DST_LANGUAGE, --dst-language DST_LANGUAGE
Desired language for the subtitles
-K API_KEY, --api-key API_KEY
The Google Translate API key to be used. (Required for
subtitle translation)
--list-formats List all available subtitle formats
--list-languages List all available source/destination languages
使用方法非常简单,将你的视频或者音频放入项目文件夹,输入命令
autosub -S zh-CN -D zh-CN 视频/音频路径这里假设你视频中的语言是国语,当然也可以是其他国别,这里是支持语言代码:
af Afrikaans
ar Arabic
az Azerbaijani
be Belarusian
bg Bulgarian
bn Bengali
bs Bosnian
ca Catalan
ceb Cebuano
cs Czech
cy Welsh
da Danish
de German
el Greek
en English
eo Esperanto
es Spanish
et Estonian
eu Basque
fa Persian
fi Finnish
fr French
ga Irish
gl Galician
gu Gujarati
ha Hausa
hi Hindi
hmn Hmong
hr Croatian
ht Haitian Creole
hu Hungarian
hy Armenian
id Indonesian
ig Igbo
is Icelandic
it Italian
iw Hebrew
ja Japanese
jw Javanese
ka Georgian
kk Kazakh
km Khmer
kn Kannada
ko Korean
la Latin
lo Lao
lt Lithuanian
lv Latvian
mg Malagasy
mi Maori
mk Macedonian
ml Malayalam
mn Mongolian
mr Marathi
ms Malay
mt Maltese
my Myanmar (Burmese)
ne Nepali
nl Dutch
no Norwegian
ny Chichewa
pa Punjabi
pl Polish
pt Portuguese
ro Romanian
ru Russian
si Sinhala
sk Slovak
sl Slovenian
so Somali
sq Albanian
sr Serbian
st Sesotho
su Sudanese
sv Swedish
sw Swahili
ta Tamil
te Telugu
tg Tajik
th Thai
tl Filipino
tr Turkish
uk Ukrainian
ur Urdu
uz Uzbek
vi Vietnamese
yi Yiddish
yo Yoruba
zh-CN Chinese (Simplified)
zh-TW Chinese (Traditional)
zu Zulu
也就是说,如果你下载了小语种国家的电影,但是不知道里面在讲些什么,也可以依赖这个库进行语音识别。
识别过程可能会有些慢,这取决于你的视频/音频的体积大小

如果想快一点,可以为autosub库手动加上自己的代理服务,打开autosub源码中的__init__.py文件,大概在99行左右使用requests库请求接口时加上proxies。
try:
resp = requests.post(url, data=data, headers=headers, proxies={
'http': 'http://127.0.0.1:4780',
'https': 'https://127.0.0.1:4780'
})
except requests.exceptions.ConnectionError:
continue识别结束后,就会将语音转储成为可见的字幕文件:
0
00:00:00,150 --> 00:00:04,380
比如现在线上怎么样是可以访问的的
1
00:00:04,381 --> 00:00:08,520
但是假设我干嘛改了你怎么办
2
00:00:08,521 --> 00:00:09,660
你还得重新打吧
3
00:00:09,661 --> 00:00:15,930
其实并不需要对有点像我们手机应用有些应用
4
00:00:15,931 --> 00:00:17,160
它是更新版本的时候
5
00:00:17,161 --> 00:00:18,660
你说要重复重新安装
6
00:00:20,010 --> 00:00:20,610
没印象
当然了,有些句子或者词汇并不准确,可能需要手工修改一下,为了让你的字幕更加精准,这样的修改工作是避免不了的。
我们得到了识别字幕后,就可以着手进行双语字幕的制作了,首先注册https://cloud.google.com/
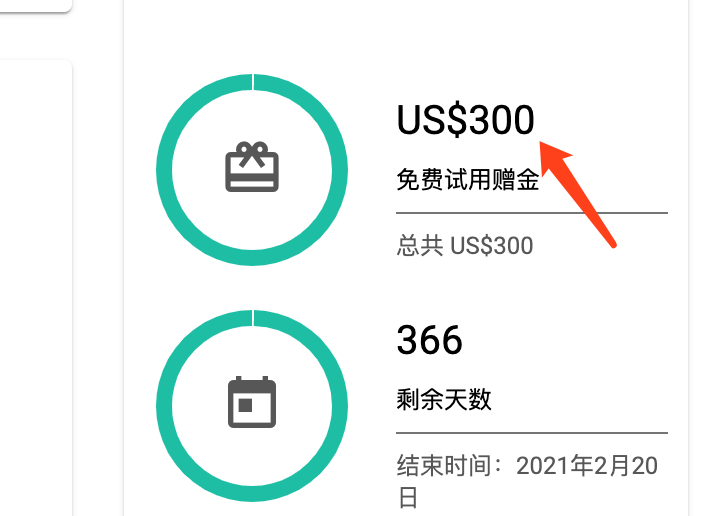
这里新用户注册成功后,都会赠送300美金,其实就是大概可以使用一年,此时点击控制台。

在默认项目中,确保你启用了谷歌翻译服务
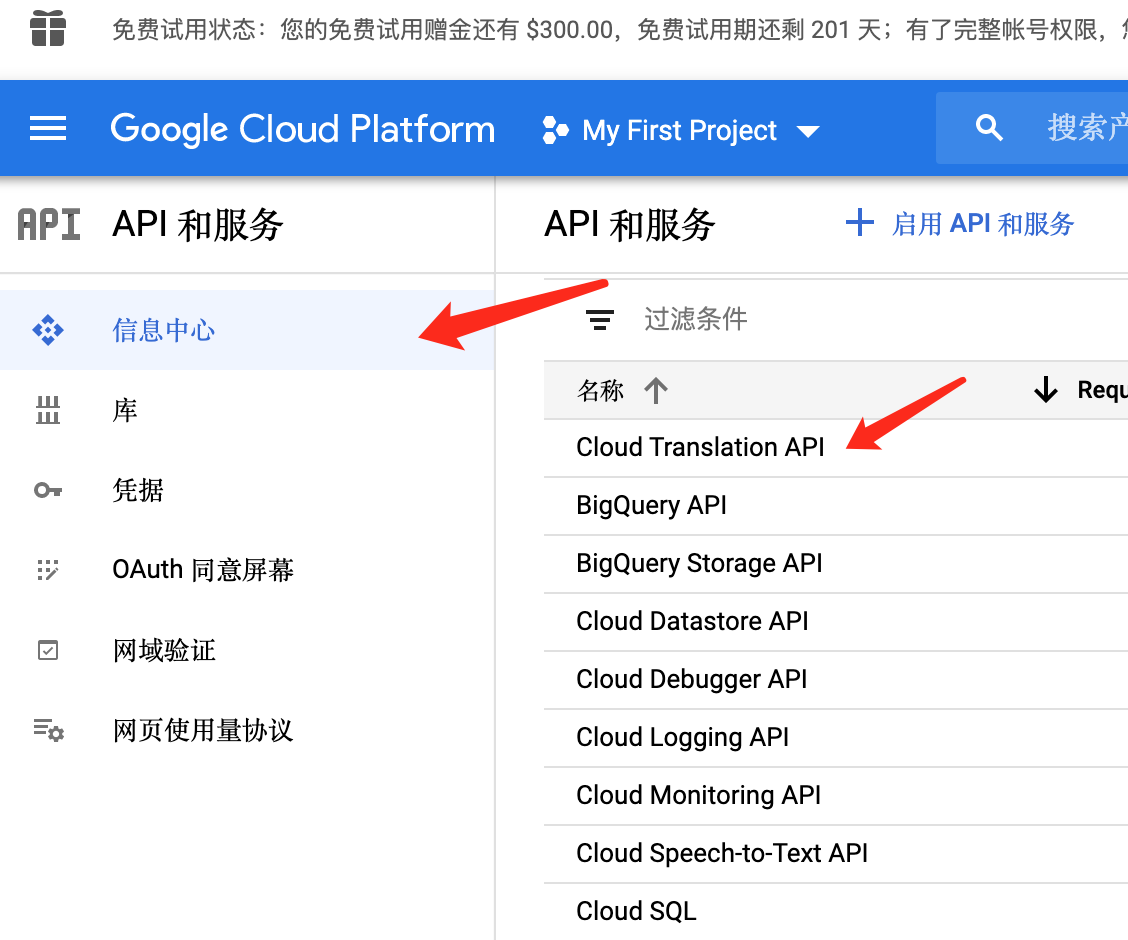
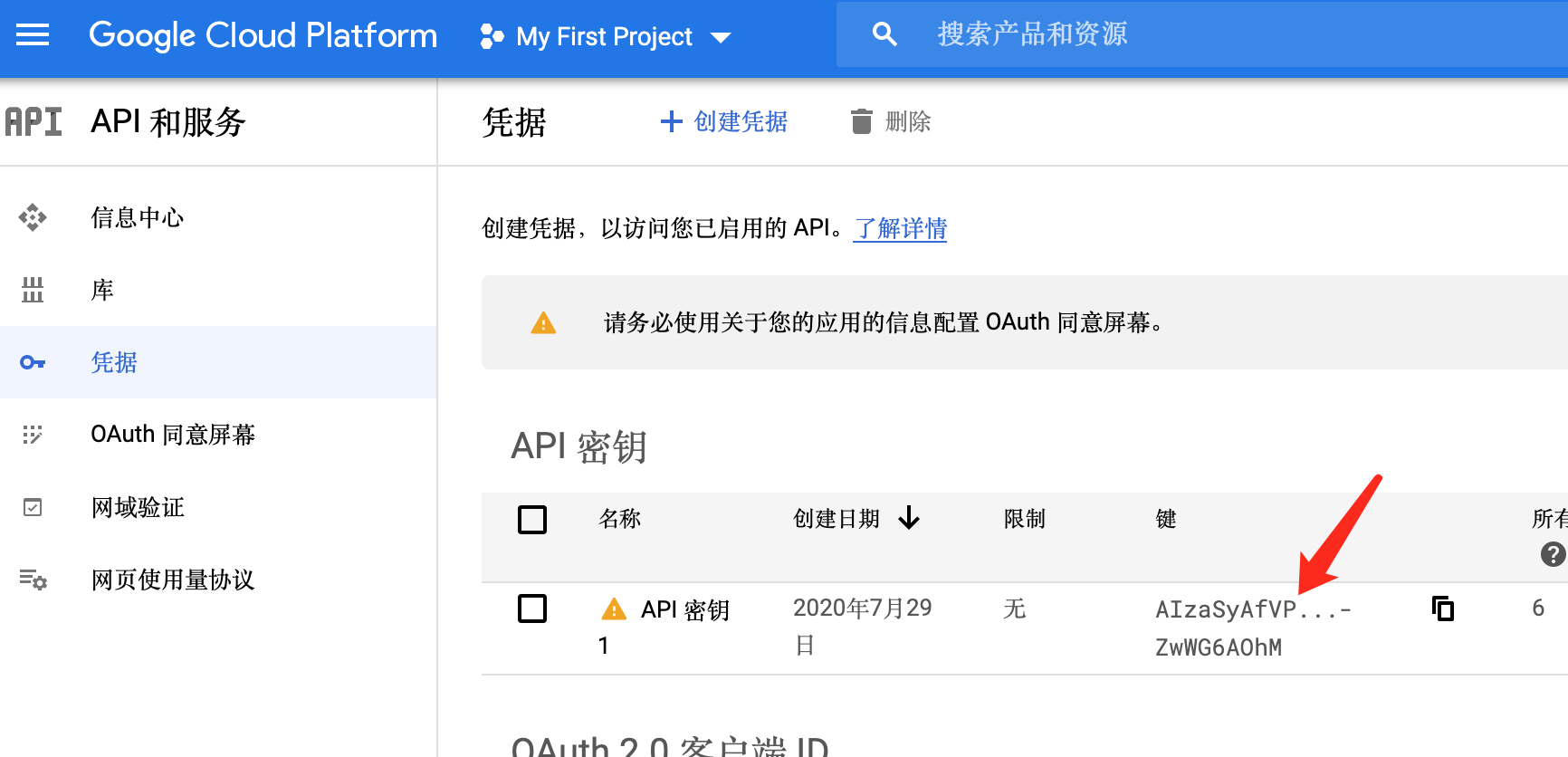
随后,点击凭据,生成一个新的API秘钥,该秘钥在调用接口时需要通过参数进行传递。
现在前置任务搞定了,我们来写个测试脚本
import requests
import json
content = "Several years ago,i went to study python in beijing"
language_type = "en"
url = "https://translation.googleapis.com/language/translate/v2"
data = {
'key': 'API秘钥', #你自己的api密钥
'source': language_type,
'target': 'zh-cn',
'q': content,
'format': 'text'
}
headers = {'X-HTTP-Method-Override': 'GET'}
response = requests.post(url, data=data, headers=headers)
res = response.json()
text = res["data"]["translations"][0]["translatedText"]
print(text)这里我们将英文翻译成国语,可以看到速度还是蛮快的。
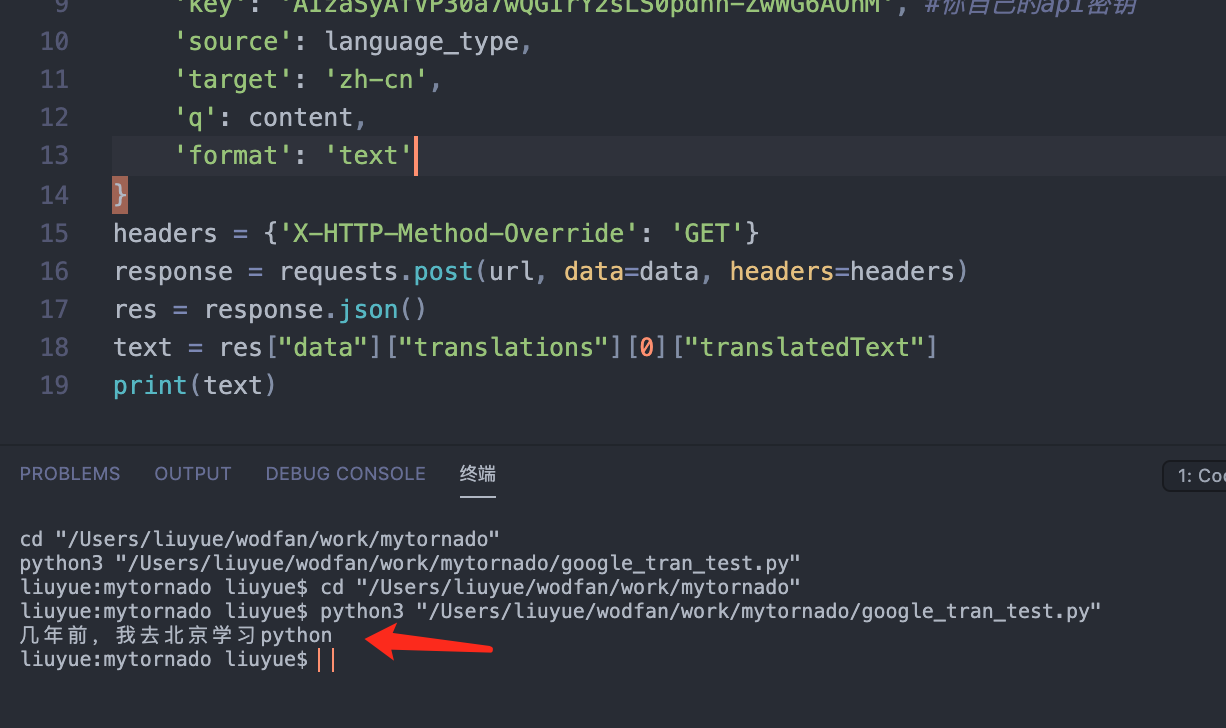
那如果针对字幕,则是针对国语翻译为英文,再通过文件追加的方式将英文写入到字幕每一行的下方。
经过翻译的字幕就是下面这样:
0
00:00:00,150 --> 00:00:04,380
For example, what is accessible online now
比如现在线上怎么样是可以访问的的
1
00:00:04,381 --> 00:00:08,520
But suppose I changed what about you
但是假设我干嘛改了你怎么办
2
00:00:08,521 --> 00:00:09,660
You'll have to try again
你还得重新打吧
3
00:00:09,661 --> 00:00:15,930
It doesn't have to be a little bit like we have apps on our phones, some apps
其实并不需要对有点像我们手机应用有些应用
4
00:00:15,931 --> 00:00:17,160
It's time to update the version
它是更新版本的时候
5
00:00:17,161 --> 00:00:18,660
You said you'd have to reinstall it
你说要重复重新安装
6
00:00:20,010 --> 00:00:20,610
No impression?
没印象
看起来还不错,但是现在双语字幕和视频还是分离的状态,我们需要将它们进行合并,于是又到了ffmpeg闪亮登场的时刻了。
ffmpeg -i test.mp4 -i my.srt -c:s mov_text -c:v copy -c:a copy output.mp4上面的命令就是将目标视频和目标字幕合并为一个新的视频output.mp4
效果是这样的:
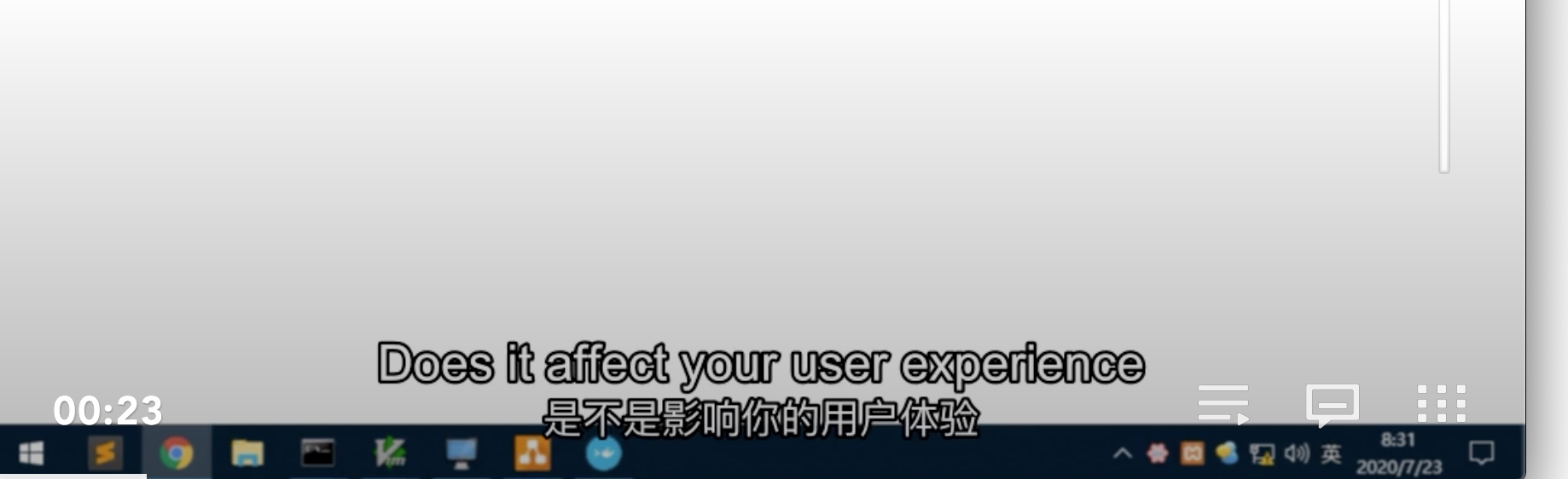
是不是感觉有点高大上,又或者,你想让字幕也炫酷一点
ffmpeg -i test.mp4 -vf "subtitles=my.srt:force_style='Fontsize=24,PrimaryColour=&H0000ff&'" -c:a copy output.mp4这里使用force_style过滤器中的subtitles选项。使用字幕文件subs.srt并使用红色字体颜色制作字体大小为24的示例。
效果是这样的:

关于字幕更多的设置方案请参照官方文档:http://ffmpeg.org/ffmpeg-all.html#subtitles-1
结语:双语字幕可以轻松的让影片的播放量得到稳定的增长,同时也可以吸引到其他国别的观众,何乐而不为,由此可见,技术改变生活的同时,也可以改变我们工作。