使用Python3.7配合协同过滤算法(base on user,基于人)构建一套简单的精准推荐系统(个性化推荐)
时至2020年,个性化推荐可谓风生水起,Youtube,Netflix,甚至于Pornhub,这些在互联网上叱咤风云的流媒体大鳄无一不靠推荐系统吸引流量变现,一些电商系统也纷纷利用精准推荐来获利,比如Amzon和Shopfiy等等,精准推荐用事实告诉我们,流媒体和商品不仅仅以内容的传播,它还能是一种交流沟通的方式。
那么如何使用python语法构造一套属于我们自己的推荐系统呢,这里推荐协同过滤算法,它隶属于启发式推荐算法(Memory-based algorithms),这种推荐算法易于实现,并且推荐结果的可解释性强,其中我们使用基于用户的协同过滤(User-based collaborative filtering):主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。举个例子,李老师和闫老师拥有相似的电影喜好,当新电影上映后,李老师对其表示喜欢,那么就能将这部电影推荐给闫老师。
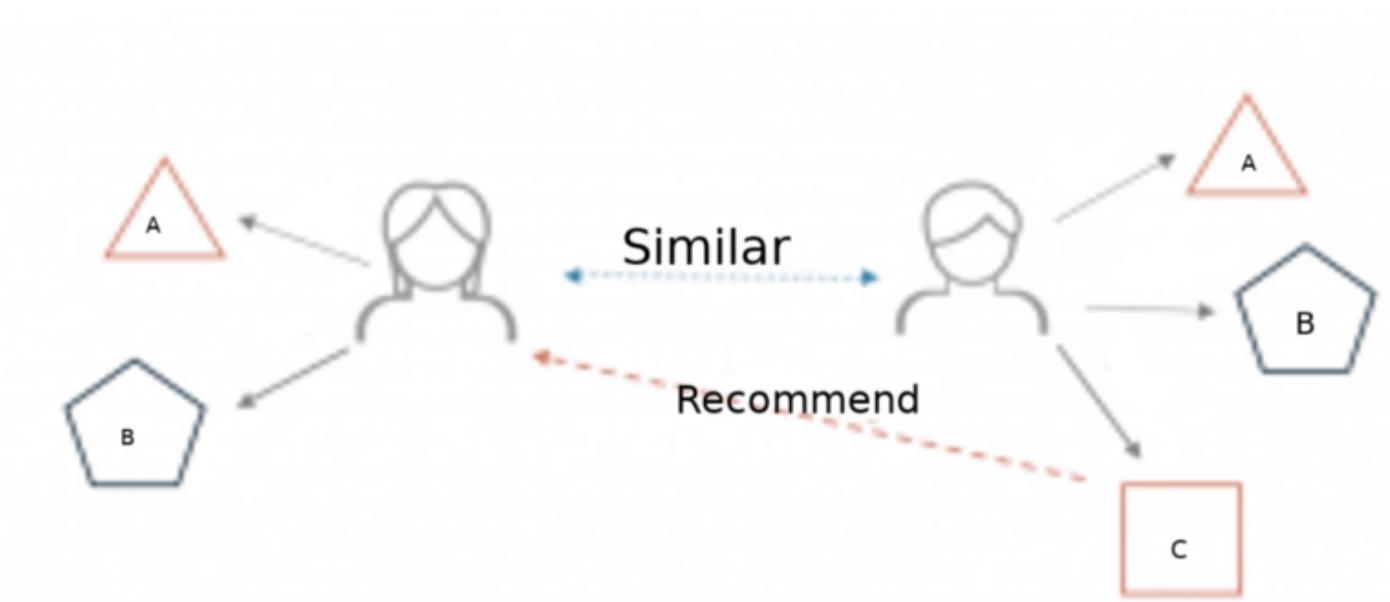
说白了就是利用商品作为纽带,判断高相似度的用户之间互相没有买过的商品,然后将其排序推荐。
假设我们是一个在线手机平台,有一些用户的购买数据和打分记录
phone.txt
1,华为p30,2.0
1,三星s10,5.0
1,小米9,2.6
2,华为p30,1.0
2,vivo,5.0
2,htc,4.6
3,魅族,2.0
3,iphone,5.0
3,pixel2,2.6用户1买了华为三星和小米三款手机,而用户而买了华为,vio,htc这三款,其中用户1和用户2的相同点是都买过华为手机,我们认为此二人具有一定的相似度,而用户3买的手机则完全不一样,所以用户3的存在可以理解为一种检查机制,用来验证推荐系统的可用性,因为以用户3的购买记录来看,理论上不应该将用户3的手机推荐给用户1和2,反过来用户1和用户2买过的手机也不会推荐给拥护3
第一步,将数据读取并格式化为字典形式,便于解析:
content = []
with open('./phone.txt') as fp:
content = fp.readlines()
# 将用户、评分、和手机写入字典data
data = {}
for line in content:
line = line.strip().split(',')
#如果字典中没有某位用户,则使用用户ID来创建这位用户
if not line[0] in data.keys():
data[line[0]] = {line[1]:line[2]}
#否则直接添加以该用户ID为key字典中
else:
data[line[0]][line[1]] = line[2]第二步,计算两个用户之间的相似度,这里使用欧几里得距离(欧式距离)
from math import *
def Euclid(user1,user2):
#取出两位用户购买过的手机和评分
user1_data=data[user1]
user2_data=data[user2]
distance = 0
#找到两位用户都购买过的手机,并计算欧式距离
for key in user1_data.keys():
if key in user2_data.keys():
#注意,distance越大表示两者越相似
distance += pow(float(user1_data[key])-float(user2_data[key]),2)
return 1/(1+sqrt(distance))#这里返回值越小,相似度越大
#计算某个用户与其他用户的相似度
def top_simliar(userID):
res = []
for userid in data.keys():
#排除与自己计算相似度
if not userid == userID:
simliar = Euclid(userID,userid)
res.append((userid,simliar))
res.sort(key=lambda val:val[1])
return res
def recommend(user):
#相似度最高的用户
top_sim_user = top_simliar(user)[0][0]
#相似度最高的用户的购买记录
items = data[top_sim_user]
recommendations = []
#筛选出该用户未购买的手机并添加到列表中
for item in items.keys():
if item not in data[user].keys():
recommendations.append((item,items[item]))
recommendations.sort(key=lambda val:val[1],reverse=True)#按照评分排序
return recommendationsprint(recommend('1')) [('vivo', '5.0'), ('htc', '4.6')]- Next Post使用Python3.7+Tornado5.1集成新浪微博三方登录(无需企业资质)
- Previous PostMac os:将Homebrew的下载源换成国内镜像增加下载速度(阿里云镜像)