Python3.7+Django2.0.4配合Mongodb打造高性能高扩展标签云存储方案
书接上回,之前有一篇文章提到了标签云系统的构建:Python3.7+jieba(结巴分词)配合Wordcloud2.js来构造网站标签云(关键词集合),但是这篇只是浅显的说明了一下如何进行切词以及前端如何使用wordcloud2.js进行前端展示,本次主要讨论下标签分词切出来之后,如何进行存储。
假设我们目前文章-标签体系的需求是这样:
每篇文章都具有唯一的标题、描述以及 URL。
每篇文章都具有一个或多个标签。
每篇文章都具有作者的名称,以及喜欢
每篇文章都有用户的评论,用户名、消息、日期时间以及评论的喜欢度。
每篇文章都可以有 0 个或多个评论。
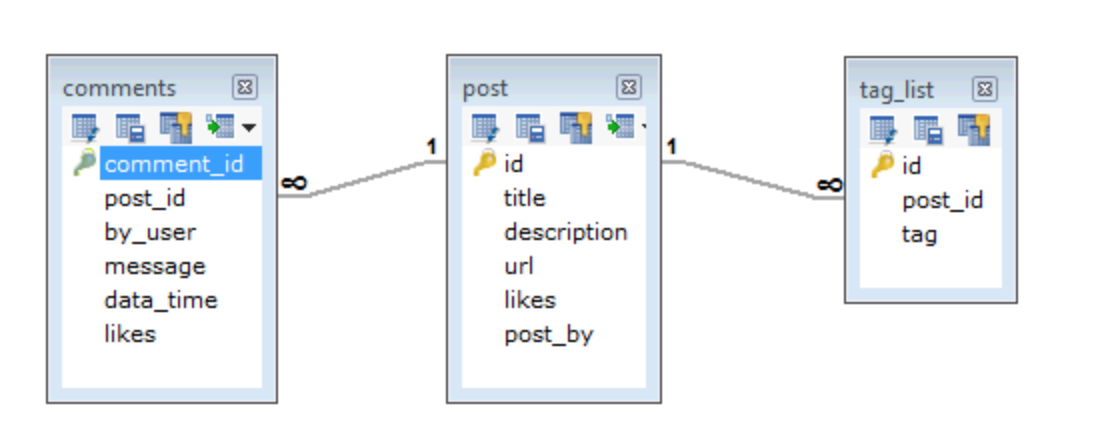
那么如果使用关系型数据库来设计,比较简单的设计方案可以是这样:

可以注意到,标签和文章的对应关系还是简单的一对多,如果做成比较灵活的多对多还需要增加一张关系表,这样就是四张表了。
如果使用nosql比如Mongodb来说,只需要一张表(聚合)就可以实现:
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}可以看到标签是由数组实现的,那么关系型数据库mysql和非关系型数据库mongodb在标签实现中本质上有什么区别呢?
关系数据库如mysql中标签云的实现是简单的,标签和文章分别在不同的表中,通过join可以比较简单的查询出标签的统计数据。 而MongoDB为快速水平扩张以及极高的性能而优化,在MongoDB中没有join,倾向于使用embedding来代替linking关系。
假设我们的需求又有了变化,普通博客变身成为具有数百万篇文章的小说站.每个小说都有许多布尔属性,大约一万个可能的属性,每篇小说都有十几个章节,假设我希望能够实时(几毫秒)请求给出的前n项任何属性组合的标签。
你会选择推荐什么解决方案?毫无疑问,如果你在寻找极具扩展性的方案,Mongodb无疑更好。
而且从业务角度上来讲,无论是通过标签查文章,还是文章查标签这样的需求,都非常灵活,当然了根据文章查标签一般没问题,一般都是根据标签查文章的时候有性能问题,如果是纯关系数据库比如mysql很难解决性能问题,所以要借助 es 索引解决。es 索引的时候可以将 tagid 用逗号分隔,可以很快的根据一个 tagid,或者多个 tagid 查询到关联的文章 id,一般文章列表都是分页的,有这些文章 id 了,再去关系数据库里面取文章就行了,但是es又是另外一件事了,回头我们再讨论。
随后使用Django2.0.4来实现,首先安装好python的mongodb操作库pymongo
pip3 install pymongo值得一提的是,它会有一个相对应bson模块 也就是说 PyMongo模块的实现是基于和它一起的bson模块的。
bson是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型;BSON有三个特点:轻量性、可遍历性、高效性,但是空间利用率不是很理想。
基于Django插入标签的视图:
import pymongo
from bson import json_util as jsonb
mongo_client = pymongo.MongoClient(host='localhost', port=27017)
from django.http import HttpResponse,HttpResponseRedirect,JsonResponse
from django.views import View
class InsertTagsHandler(View):
def get(self,request):
db = mongo_client.test12
table = db.test12
res = table.find({"title":'123'}).count()
print(res)
if res > 0:
result = '重复数据'
return HttpResponse(json.dumps({'result':result},ensure_ascii=False))
else:
table.insert({'title':'123','desc':['123','123']})
return HttpResponse(json.dumps({'result':'添加成功'},ensure_ascii=False))基于django通过文章查询标签
class FindArticleHandler(View):
def get(self,request):
db = mongo_client.test12
table = db.test12
res = table.find_one({"title":'123'},{"desc":1})
return HttpResponse(jsonb.dumps(res,ensure_ascii=False))基于django分组查询获取所有标签以及标签出现次数的统计
class TagsStatHandler(View):
def get(self,request):
db = mongo_client.test12
table = db.test12
pipeline = [{'$unwind':"$tags"},{'$group': {'_id': "$tags", 'count': {'$sum': 1}}},]
res = table.aggregate(pipeline)
return HttpResponse(jsonb.dumps(res,ensure_ascii=False))基于django通过标签反查文章
class Tags2ArticleHandler(View):
def get(self,request):
db = mongo_client.test12
table = db.test12
res = table.find({"tags":{'$in':["123"]}})
return HttpResponse(jsonb.dumps(res,ensure_ascii=False))结语:经此一役,Mongodb的特点跃然纸上:结构灵活,表结构更改相对自由,不用每次alter的时候付出代价,适合业务快速迭代,而且json原生和大多数的语言有天然的契合。还支持数组,嵌套文档等数据类型。