关于Python3异步非阻塞Web框架Tornado:真实的异步和虚假的异步

我们知道Tornado 优秀的大并发处理能力得益于它的 web server 从底层开始就自己实现了一整套基于 epoll 的单线程异步架构,其他 web 框架比如Django或者Flask的自带 server 基本是基于 wsgi 写的简单服务器,并没有自己实现底层结构。而tornado.ioloop 就是 tornado web server 最底层的实现。
ioloop 的实现基于 epoll ,那么什么是 epoll? epoll 是Linux内核为处理大批量文件描述符而作了改进的 poll / select 。
那么到底什么是 poll / select ? socket 通信时的服务端,当它接受( accept )一个连接并建立通信后( connection )就进行通信,而此时我们并不知道连接的客户端有没有信息发完。 这时候我们有两种选择:
一直在这里等着直到收发数据结束;
每隔一会儿来看看这里有没有数据;
第一种办法虽然可以解决问题,但我们要注意的是对于一个线程进程同时只能处理一个 socket 通信,其他连接只能被阻塞。 显然这种方式在单进程情况下不现实。
第二种办法要比第一种好一些,多个连接可以统一在一定时间内轮流看一遍里面有没有数据要读写,看上去我们可以处理多个连接了,这个方式就是 poll / select 的解决方案。 看起来似乎解决了问题,但实际上,随着连接越来越多,轮询所花费的时间将越来越长,而服务器连接的 socket 大多不是活跃的,所以轮询所花费的大部分时间将是无用的。为了解决这个问题, epoll 被创造出来,它的概念和 poll 类似,不过每次轮询时,他只会把有数据活跃的 socket 挑出来轮询,这样在有大量连接时轮询就节省了大量时间。
具体说说select:select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。
while true {
select(streams[])
for i in streams[] {
if i has data
read until unavailable
}
}select的优点是支持目前几乎所有的平台,缺点主要有如下2个:
1)单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。
2)select 所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。
poll则在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
epoll是Linux 2.6 开始出现的为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。另一点原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
while true {
active_stream[] = epoll_wait(epollfd)
for i in active_stream[] {
read or write till
}
}两相对比,可以看出来,epoll只轮询数据活跃的socket,性能自然就比较高了。
而Tornado其实默认是同步阻塞机制的,为了能够实现异步,你就必须使用异步的写法才可以,这里有一个简单的demo:
from tornado.web import RequestHandler
import tornado.ioloop
import tornado.httpclient
import tornado.web
import requests
#异步任务
class AsyncHandler(RequestHandler):
@tornado.web.asynchronous
def get(self):
http_client = tornado.httpclient.AsyncHTTPClient()
http_client.fetch("http://baidu.com",
callback=self.on_fetch)
def on_fetch(self, response):
print(response)
self.write('done')
self.finish()
#同步任务
class SyncHandler(RequestHandler):
def get(self):
response = requests.get("http://baidu.com")
print(response)
self.write('done')
def make_app():
return tornado.web.Application(handlers=[
(r'/async_fetch', AsyncHandler),
(r'/sync_fetch', SyncHandler),
],debug=True)
if __name__ == '__main__':
app = make_app()
app.listen(8000)
tornado.ioloop.IOLoop.current().start()
可以看到异步任务我们使用了(回调)和@tornado.web.asynchronous
@tornado.web.asynchronous 并不能将一个同步方法变成异步,所以修饰在同步方法上是无效的,只是告诉框架,这个方法是异步的,且只能适用于HTTP verb方法(get、post、delete、put等)。@tornado.web.asynchronous 装饰器适用于callback-style的异步方法,对于用@tornado.web.asynchronous 修饰的异步方法,需要主动self.finish()来结束该请求,普通的方法(get()等)会自动结束请求在方法返回的时候。
对比下效率:使用ab命令发送500个请求,每秒50个 ab -n 500 -c 50
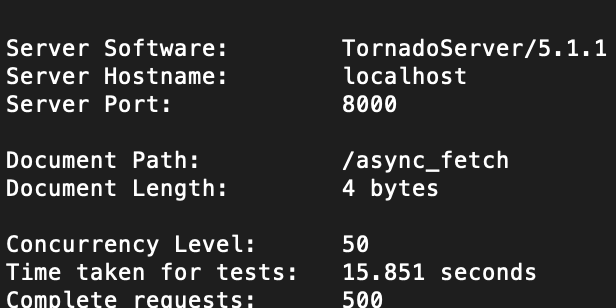
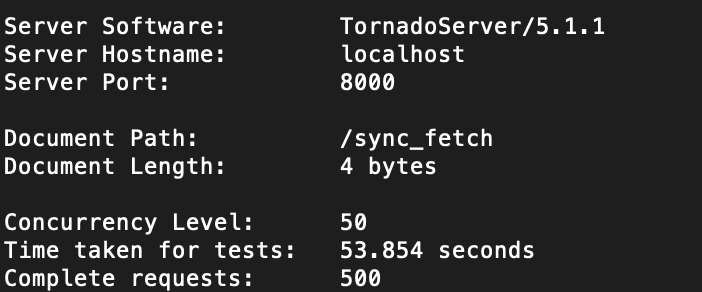
结果显而易见,异步效率更高,15秒完成了同步需要50秒的任务。
但是,要想达到异步效果,就必须使用异步写法,让io操作变成异步io,而异步写法对于后台研发的综合素质要求比较高,那么能不能用同步的写法达成异步效果呢?当然可以,就是使用celery+tornado
最后总结一下:
Tornado的异步原理: 单线程的torndo打开一个IO事件循环, 当碰到IO请求(新链接进来 或者 调用api获取数据),由于这些IO请求都是非阻塞的IO,都会把这些非阻塞的IO socket 扔到一个socket管理器,所以,这里单线程的CPU只要发起一个网络IO请求,就不用挂起线程等待IO结果,这个单线程的事件继续循环,接受其他请求或者IO操作,如此循环。
说人话:poll/select: 在一个育婴室内,护士会对育婴室内所有的婴儿挨个check一遍,如此往复。epoll:护士会使用高科技设备对婴儿进行监听,并且只会check生命体征有问题(活跃)的婴儿,如此往复。
另外,对于如果面对超高的并发请求(qps上万),仅仅采用 epoll 模型是不够的,我们还必须使用多进程多线程等方式来充分利用系统资源,这就引出了nginx反向代理tornado进行负载均衡。
- Next Post在centos7.6上利用docker-compose统一管理容器和服务
- Previous Post使用python3和高性能全文检索引擎Redisearch进行交互