人工智能机器学习底层原理剖析,人造神经元,您一定能看懂,通俗解释把AI“黑话”转化为“白话文”
按照固有思维方式,人们总以为人工智能是一个莫测高深的行业,这个行业的人都是高智商人群,无论是写文章还是和人讲话,总是讳莫如深,接着就是蹦出一些“高级”词汇,什么“神经网络”,什么“卷积神经”之类,教人半懂不懂的。尤其ChatGPT的风靡一时,更加“神话”了这个行业,用鲁迅先生形容诸葛武侯的话来讲:“多智而近妖”。
事实上,根据二八定理,和别的行业一样,人工智能行业内真正顶尖的天才也就是20%,他们具备真正的行业颠覆能力,可以搞出像ChatGPT这种“工业革命”级别的产品,而剩下的80%也不过就是普通人,每天的工作和我们这些人一样,枯燥且乏味,而之所以会出现类似“行业壁垒”的现象,是因为这个行业的“黑话”太多了,导致一般人听不懂,所谓“黑话”可以理解为行业术语,搞清楚了这些所谓的行业术语,你会发现,所谓的“人工智能”,不过也就是个“套路活儿”。
本次我们试图使用“白话文”来描摹人工智能机器学习的底层逻辑,并且通过Golang1.18来实现人造神经元的原理。
人造神经元 Neural
现在业内比较流行的,比如Transformer模型、GPT模型、深度学习、强化学习、卷积神经网络等等,无论听起来多么高端大气上档次,说出大天去,它也是神经网络架构,换句话说它们的底层都一样,类比的话,就像汽车行业,无论是汽油驱动还是电驱动、三缸发动机还是六缸发动机、单电机还是双电机,混合动力还是插混动力,无论汽车主机厂怎么吹牛逼,无论车评人怎么疯狂恰饭,厂商造出来的车最终还是一个最基本的汽车架构,说白了就是一个底盘四个轮儿,你再牛逼,你也逃不出这个基本架构。
所以说,机器学习的基本架构是神经网络架构,神经网络由大量的人工神经元组成,它们联结之后就可以进行所谓的“机器学习”。所以,必须搞清楚什么是神经元,才能弄懂神经网络。
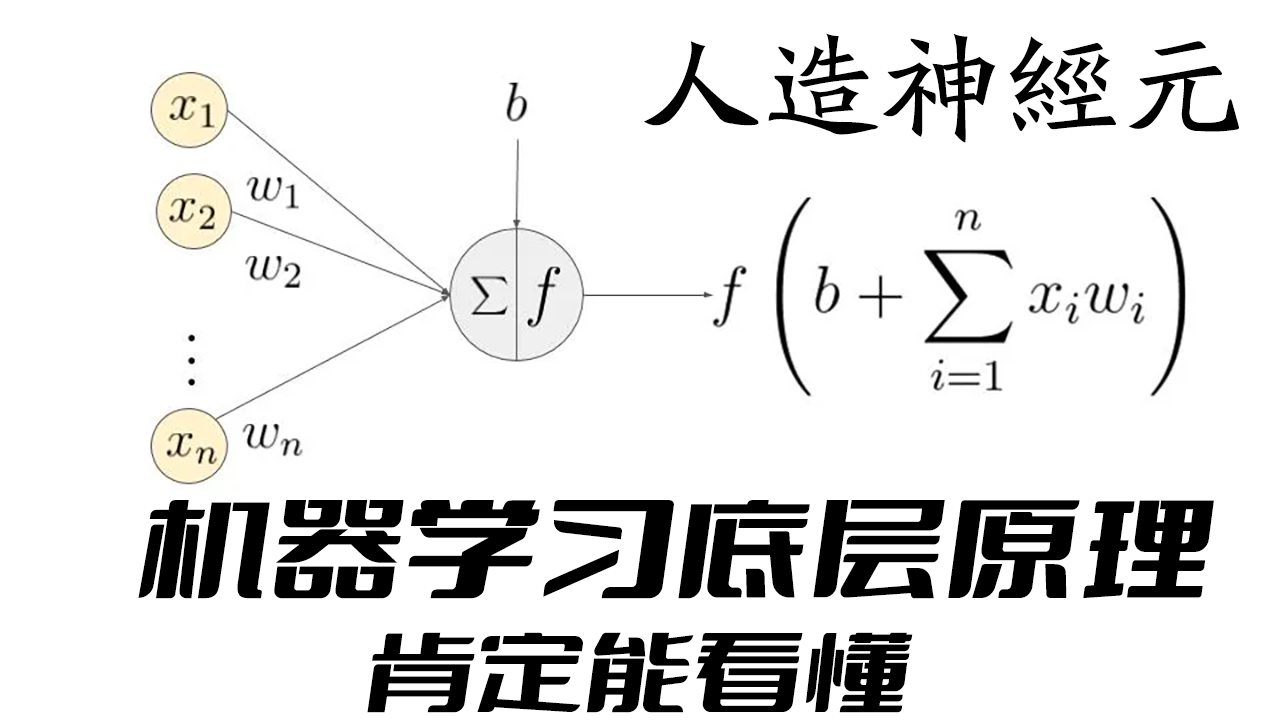
神经元是神经网络架构中最微小的单位,也是最小的可训练单位,一个基本的神经元结构是下面这样的:
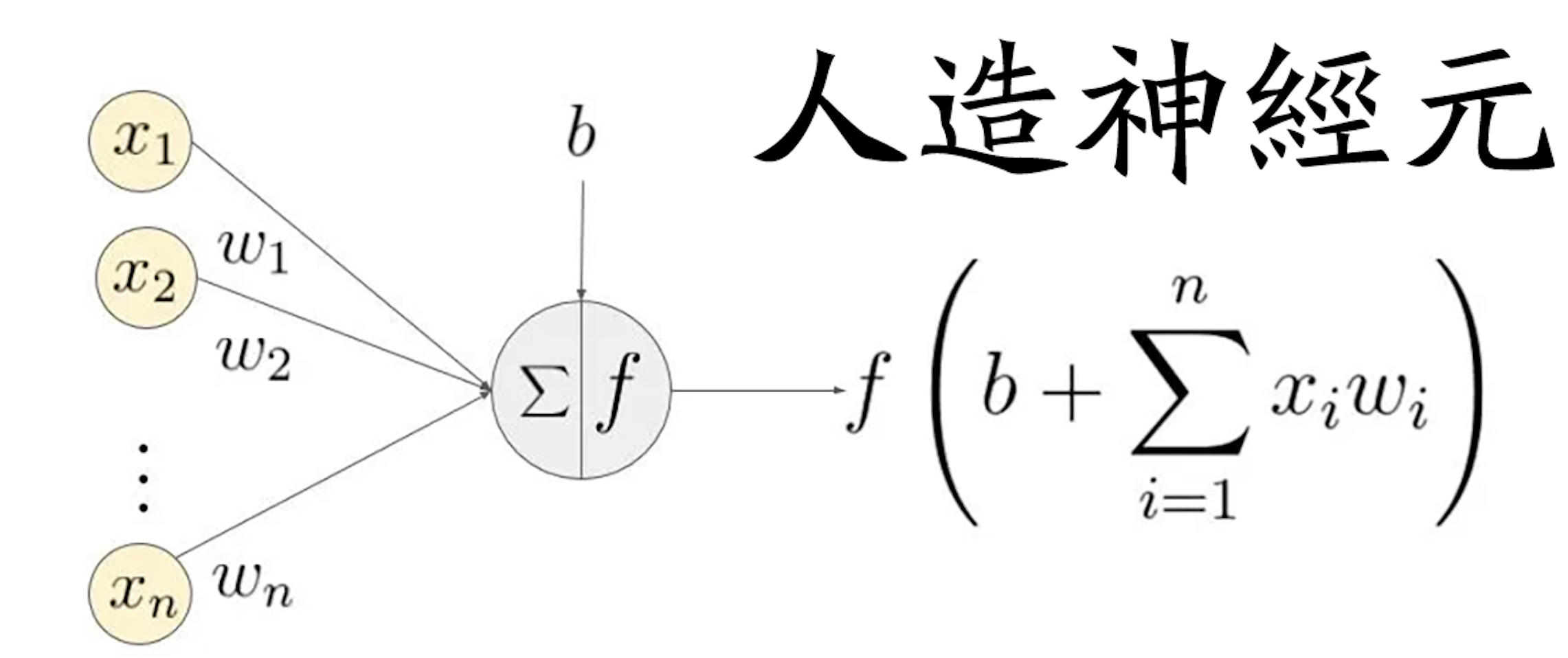
毋庸讳言,大多数人看见这个基本上都会瞬间放弃,数学公式简直就是开发界的洪水猛兽,其劝退能力堪比艾尔登法环中的大树守卫,我们的机器学习之旅还没开始,就已经结束了。

那么我们把这个玩意儿翻译成大多数人能看懂的样子:f( sum( x*w) + b )
x代表输入的数据,w代表权重,sum代表求和,b代表偏差,f代表激活函数,最后这个公式运行的结果,就是机器学习的结果。
简单往里头套点数据,比如我希望机器学习的结果是10,那么,x、w、和b分别应该是什么才能让结果变为10呢?如果 x=2 w=4 b = 2 就是我们想要的结果。这也就是最基本的线性回归,我们只处理一个维度的数据,因为结果已经显而易见了,我们已经不需要机器学习了,因为靠猜也能猜出来结果是什么。
但是生产环境中,x并非是单维度,而是多维度的,比如x1、x2、x3.....组成的矩阵,但无论是多维度还是单维度,计算公式用的还是一样的,每一个x对应一个权重w,所以是xn*wn。
说白了,x就是一个多维特征,类比的话,假如我们想让电脑智能识图,比如识别一只猫,那么x就是猫的特征,比如形态、颜色、眼睛、叫声等等,作为多维度的输入特征x,喂给电脑,让电脑给出识别结果,这就是简单的机器学习处理分类问题。
这里需要注意的是,x作为特征参数,并不是越多越好,而是特征越明显越好,举个例子,你想让AI去识别鲁迅的文章,那提供的特征最好应该具备鲁迅文章的特点,而不是全量输入,因为鲁迅就算再“鲁迅”,他写的文字也会和别人重复,也就是说并不是每句话都是他独有的,如果把他所有的文章都喂给电脑,可能就会产生“噪声”,影响机器学习的结果。
另外应该知道的是,x参数特征并不是我们认为的单词或者汉字,而是一串单精度区间在0-1之间的浮点数字,也就是所谓的“向量”,因为只有数字才能套着神经元公式进行计算。
所以所有的文本特征在进行神经元计算之前,必须通过一些方法进行“向量化”操作。说白了就是把汉字转化为数字,就这么简单。
另外这也就证明了,电脑真的没有思想,它不理解什么是猫,或者谁是鲁迅,它就是在进行计算,而已。
随后是w,w指的是权重,权重是指神经元接收到的输入值的重要性,这些输入值通过乘以对应的权重,被加权求和作为神经元的输入。权重值越大,表示该输入在神经元的输出中所占的比重越大。说白了,猫的所有特征的权重并不是统一的,比如黑夜里突然一个东西跳了出来,你怎么判断它是什么物种?很明显,一声“喵呜”我们就可以立刻断定这是一只猫,所以叫声特征的权重一定大于其他特征的权重。
最后是b,也就是偏差(bias),偏差通常是一个实数,与神经元的权重一样,也是通过训练神经网络而调整的参数。偏差的作用是在神经元的输入上增加一个常量,以调整神经元的激活阈值。如果没有偏差,那么神经元的激活函数将仅仅取决于加权和的值,而无法产生任何偏移。
说白了,b就是让x * w的值更活一点,让它不是“死”的数。
最后说说f 也就是激活函数,激活函数通常具有非线性的特性,这使得神经网络能够拟合非线性的复杂函数,从而提高其性能和准确度。
说白了,如果没有激活函数,我们的权重计算就是“线性”的,什么叫线性?如果把x特征从1开始输入,一直到100,然后将计算结果绘制成图:
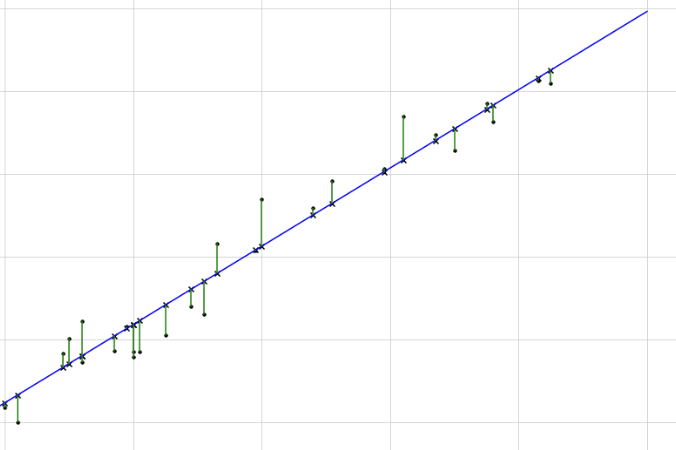
我们会发现计算结果是一根直线,这显然不符合客观规律,更符合生物特征的形态应该是“曲线”,所以说白了,激活函数f的作用就是把“直线”变成“曲线”。
最后,我们把神经元公式改造成方便我们理解的形式:期望结果 = 激活函数( 求和(特征 * 权重) + 偏差 )。
如果用代码实现这个公式:
func neuron(inputs []float64, weights []float64, bias float64) float64 {
if len(inputs) != len(weights) {
panic("inputs and weights must have the same length")
}
sum := bias
for i := 0; i < len(inputs); i++ {
sum += inputs[i] * weights[i]
}
return sum
}这个函数接收两个长度相同的浮点数数组 inputs 和 weights,以及一个偏置值 bias。它通过将每个输入值乘以其对应的权重,加上偏置值,得到神经元的加权和。最后,函数返回这个加权和作为神经元的输出值。
使用这个函数时,可以将输入数据和权重作为参数传递给它。例如,假设我们有一个二分类问题,输入数据有两个特征:x1和x2,并且我们有一个包含两个权重和一个偏置的神经元。那么可以这样调用神经元公式:
inputs := []float64{x1, x2}
weights := []float64{w1, w2}
bias := b
output := neuron(inputs, weights, bias) 这里返回神经元的输出值,所以,谁说学习人工智能必须得用Python?我们就骄傲地使用Golang。
机器学习,到底怎么学习
机器学习的过程就是上文中神经元公式的使用过程,第一步收集所有的特征数据,然后进行权重分配,最后向量化操作,把文本数据转换为计算机能计算的浮点数,随后加权求和,之后加一个偏差(bias),最后过一下激活函数,最终得到一个期望结果,就完事了。
难吗?不难,普通人连猜带蒙也能做。
但事实上,这只是原理,也就是最基本的东西,一般人都能掌握,比如打篮球,规则非常简单,核心就是运球和投篮,无对抗下小学生也能瞬间掌握,但小学生没法去打NBA级别的比赛,因为很多高端的篮球技术是构筑于运球和投篮的,需要经年累月的练习和自身天赋的加成,所以全世界能打NBA的就那么几百人,而已。
同理,机器学习的过程也并非如此简单,通过特征输入,经过神经元公式,得到的结果真的一定是我们所期望的结果吗?
其实未必,机器学习还包括两个极其重要的概念:前向传播和反向传播。
前向传播是指将输入数据从神经网络的输入层传递到输出层的过程。在前向传播过程中,输入数据通过神经网络的每一层,每个神经元都会对其进行一定的加权和激活函数计算,最终得到输出层的输出值。这个过程也被称为“正向传播”,因为数据是从输入层依次向前传播到输出层。
反向传播是指在前向传播之后,计算神经网络误差并将误差反向传播到各层神经元中进行参数(包括权重和偏置)的更新。在反向传播过程中,首先需要计算网络的误差,然后通过链式法则将误差反向传播到各层神经元,以更新每个神经元的权重和偏置。这个过程也被称为“反向梯度下降”,因为它是通过梯度下降算法来更新神经网络参数的。
说白了,前向传播就是由特征到结果的过程,反向传播则是逆运算,用结果反推过程。
回到分类问题,我们输入了猫的特征和特征权重,经过计算,结果未必是猫,可能是狗,或者是耗子,也可能是别的什么东西,但这不重要,重要的是我们需要拿到一个结果的误差,这个误差越小越好,而反向传播就是帮我们推算误差到底有多大的方法。
而误差的大小就取决于特征的输入,导致机器学习结果错误的根源是参数,此时,我们需要调整参数的输入,从而减小误差值,这也就是人工智能行业从业人员经常说的“调参”。
比如,我们期望结果是猫,结果计算机返回狗,那么调整参数,结果返回熊猫,那么就说明调大发了,继续调整,直到计算机返回结果:猫。
在 Golang1.18 中,可以通过以下代码实现反向传播:
func backpropagation(inputs []float64, targets []float64, network *Network, learningRate float64) {
// 1. 前向传播,计算每个神经元的输出值
outputs := feedforward(inputs, network)
// 2. 计算输出层的误差
outputErrors := make([]float64, len(outputs))
for i := range outputs {
outputErrors[i] = outputs[i] - targets[i]
}
// 3. 反向传播误差,计算每个神经元的误差值
for i := len(network.layers) - 1; i >= 0; i-- {
layer := network.layers[i]
errors := make([]float64, len(layer.neurons))
// 3.1. 计算神经元的误差值
if i == len(network.layers)-1 {
// 输出层的误差
for j := range layer.neurons {
errors[j] = outputErrors[j] * sigmoidPrime(layer.neurons[j].output)
}
} else {
// 隐藏层的误差
for j := range layer.neurons {
errorSum := 0.0
nextLayer := network.layers[i+1]
for k := range nextLayer.neurons {
errorSum += nextLayer.neurons[k].weights[j] * nextLayer.neurons[k].error
}
errors[j] = errorSum * sigmoidPrime(layer.neurons[j].output)
}
}
// 3.2. 将误差值保存到神经元中
for j := range layer.neurons {
layer.neurons[j].error = errors[j]
}
}
// 4. 更新神经网络的权重和偏置
for i := range network.layers {
layer := network.layers[i]
// 4.1. 更新权重
for j := range layer.neurons {
for k := range layer.neurons[j].weights {
if i == 0 {
// 输入层的权重
layer.neurons[j].weights[k] -= learningRate * layer.neurons[j].error * inputs[k]
} else {
// 隐藏层和输出层的权重
prevLayer := network.layers[i-1]
layer.neurons[j].weights[k] -= learningRate * layer.neurons[j].error * prevLayer.neurons[k].output
}
}
// 4.2. 更新偏置
layer.neurons[j].bias -= learningRate * layer.neurons[j].error
}
}
}这个函数接收输入数据 inputs、目标数据 targets、神经网络 network 以及学习率 learningRate 作为参数。它首先调用 feedforward 函数进行前向传播,计算每个神经元的输出值。然后,它计算输出层的误差,通过误差反向传播,计算每个神经元的误差值,并将其保存到神经元中。
接下来,函数根据误差值和学习率更新神经网络的权重和偏置。在更新权重时,需要根据神经元所在的层来选择更新的权重类型(输入层、隐藏层或输出层),然后根据误差值和输入数据或上一层神经元的输出值来更新权重。在更新偏置时,只需要根据误差值和学习率来更新即可。
总的来说,这个函数实现了反向传播的所有步骤,可以用于训练神经网络并提高其准确度和性能。
结语
大道不过三俩句,说破不值半文钱,所谓人工智能机器学习就这么回事,没必要神话,也无须贬低,类比的话,就像餐饮行业的厨师岗,所谓做菜,底层原理是什么?就是食材和火候,掌握了做菜的底层原理,就能做出好菜,其他的,比如刀工、颜色等等,不过就是锦上添花的东西,而已。
所以机器学习就是做菜,做出来的东西可能不尽如人意,就得不停地调整食材的搭配和火候的大小,所谓机器学习的最重要技巧,其实是特征的提取以及参数的调整,所谓大道至简,殊途同归。